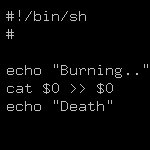
Я тут подумал, наверняка ведь есть много таких же как я, которые плохо знают всякие sort, unique, awk, sed, зато отлично помнят все про sql.
И каждый раз, когда надо почитать логи, вспоминание стандартных подходов занимает драгоценное время. Почему бы не написать утилиту с sql интерфейсом?
% cat file | awk {'print $1 $3 $7'}
% cat file | sqllp 'select 1 date, 3 ip, 4 url'
% cat file | awk {'print $3'} | sort -u
% cat file | sqllp 'select distinct 1 ip'
% cat file | sqllp 'select 1 ip, count(*) n group by ip order by n desc limit 10'
% cat file | sqllp 'select * where 4 ilike '%assets%'
И т.д. и т.п. Есть подозрение что такое уже сделали, может кто знает как поискать?