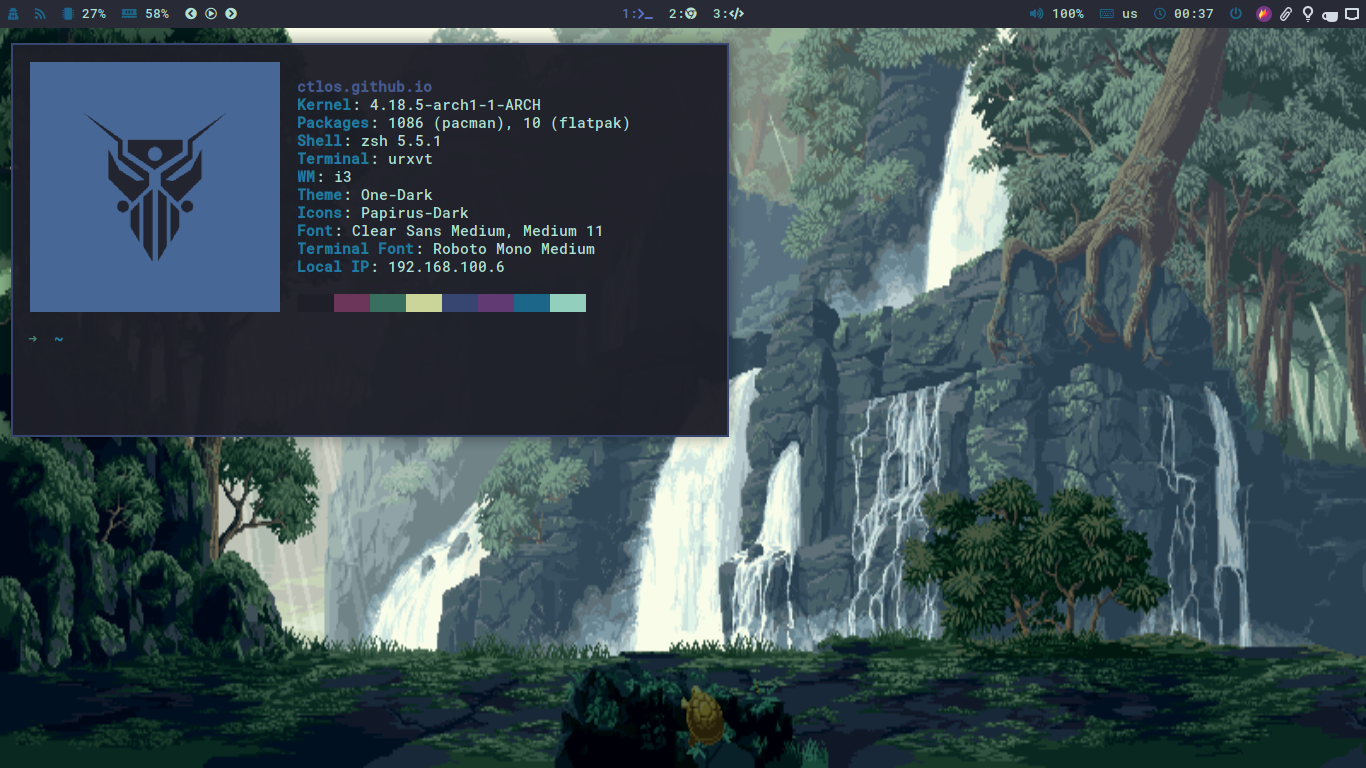
i3 gaps Arch Linux
Галерея — Скриншоты
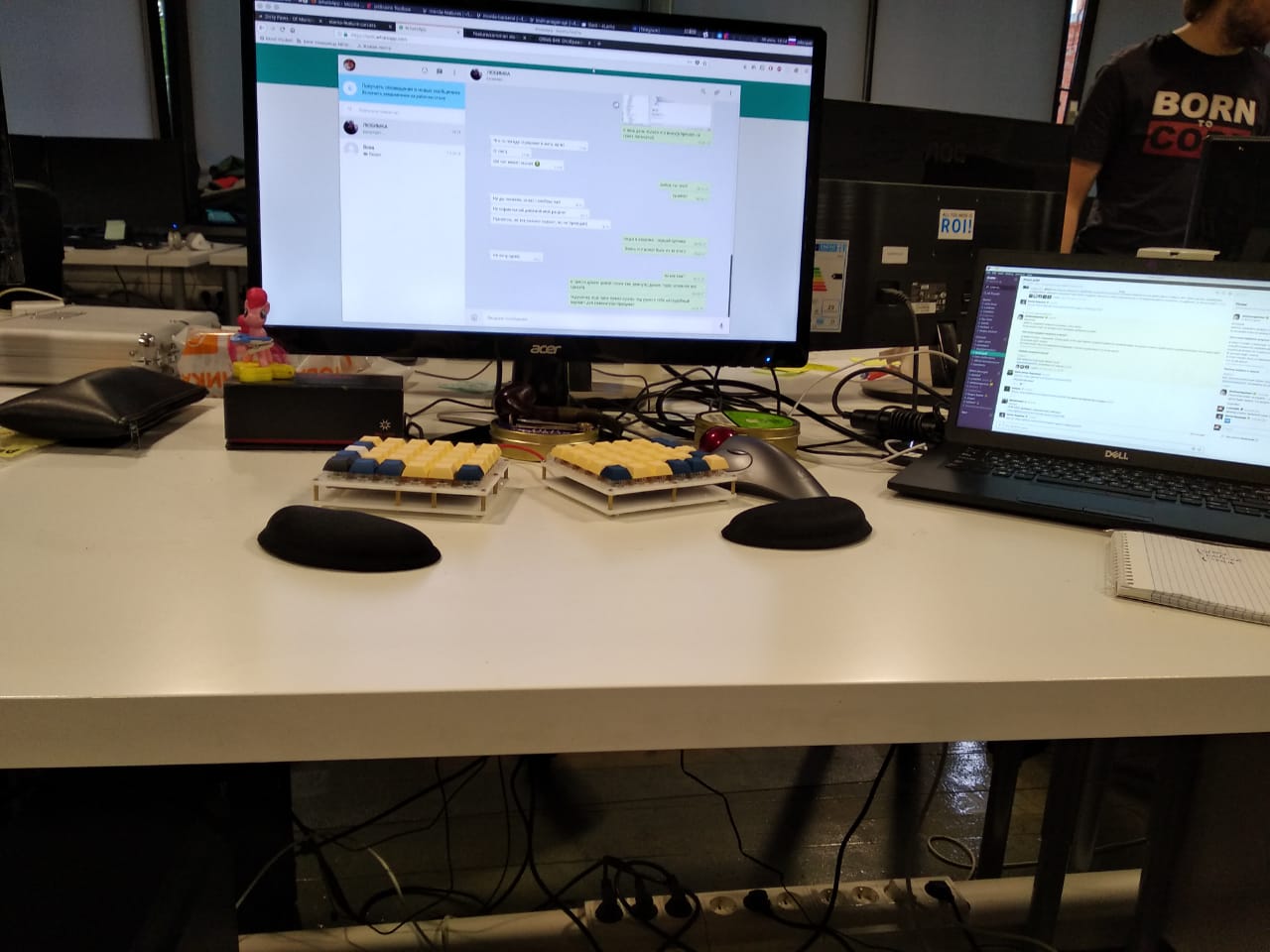
Мое реальное рабочее место, работаю Scala-разработчиком.
В роли компьютера использую свой ноутбук Dell Latitude 7490, увеличив ему оперативную память до 24Гб(почти не падаю в ООМ). В качестве операционной системы - XUbuntu 17.10.
Попсовый трекбол из магазина хотел бы заменить на что-нибудь другое, но пока не решил на что.
Из интересного - клавиатура - Nyquist, собранная собственноручно. Печатные платы брал с сайта keeb.io - там вполне себе приемлемые цены, а наличие схемы и свободной прошивки(на базе QMK) делают ее вполне себе Open Hardware.
В качестве гостевой клавиатуры и мышки выступает ноутбук.
HHKB Pro 2 так и осталась в моих фаворитах, но она так же стала фаворитом моей жены, поэтому - я работаю на найквисте, а она на HHKB.
В кадре так же имеются: пинки пай из старой коллекции Хэппи Милл, датский трубочный табак, а так же пара Петерсонов(внимание: курение вредит вашему здоровью).
Решил установить Elasticsearch на Linux и запускать все три программы: Elasticsearch, Logstash, Kibana в Docker контейнерах.
Запустил все 3 контейнера и привязял их к Elasticsearch:
docker run -d --name kibana -p 5601:5601 --link elasticsearch:docker.elastic.co/elasticsearch/elasticsearch -d docker.elastic.co/kibana/kibana:5.3.0
docker run -d --name logstash -p 5400:5400 -v ~/pipeline/:/home/name/ --link elasticsearch:docker.elastic.co/elasticsearch/elasticsearch -d docker.elastic.co/logstash/logstash:5.3.0
Создал файл 'logstash.conf' и указал его путь (/home/name/) в комманде при запуске Logstash контейнера:
input {
file {
path => "/home/name/access.log" # sample Apache log file on my local
type => "apachelogs"
start_position => "beginning"
}
}
filter {
if [type] == "apache-access" {
grok {
match => [ "message", "%{COMBINEDAPACHELOG}" ]
}
}
}
output {
elasticsearch { embedded => true }
}
Kibana показывает, что видит и Elasticsearch и Logstash, но Logstash не обнаружил лог-файл 'access.log'.
Не могли бы подсказать в чём проблема?
Перемещено leave из development
Посмотрел запись доклада Алименкова про ООП и ненужность наследования, надо бы прокомментировать что-то.
Вот ссылка на его видео: https://www.youtube.com/watch?v=G6LJkWwZGuc, предлагаю посмотреть, прежде чем вайнить :3
Вкратце, автор осуждает наследование, считает что оно зло, предлагает заменять на композицию.
Имхо, чтобы начать понимать наследование, нужно почитать немного википедию, вспомнить основы матлогики и сделать простейшие выводы о том, как мир выглядит сквозь призму ООП-моделирования. После этого тебе уже не нужна лекция Алименкова, ты можешь смотреть на любые вещи, предметы, события, и видеть их сквозь ООП. Смотришь на стол, ложку и мужской половой предмет - и везде видишь теоремы об изоморфизме в записи Java-классами.
Вместо этого для большинства коллег сейчас ООП - это кода ты в IDE протыкал кнопочку «отнаследоваться от класса и переопределить вот такие методы», когда функциональности существующего класса не хватает. Особенно хорошо видно на собеседованиях: тебя спрашивают какую-то чепуху типа «всех методов ArrayList» (вероятно чтобы потом нажать кнопочку «доопределить»), а о самой сути работы, которая как раз есть ООП моделирование, почему-то не спрашивают.
И потом при написании кода начинается история про слепых мудрецов, натолкнувшихся на слона. Только они не хотели изучить слона, они сразу хотели на нем ездить, или хотя бы чтобы он не мешал им пройти. В результате такой вверх ногами постановки возникают странные языки без ООП и метопрограммирования просто для того, чтобы его не было. Вот эти анонимные филды, вложенные структуры в Гошке. Слон, не мешай проезду.
В качестве примера, мне кажется важным: ООП в Java есть продукт теории типов, и она хорошо решает ситуации, когда нужно разобраться с чем-то типа полиморфизма подтипов. Отсюда принципы SOLID, в частности принцип подстановки Лисков.
Но как только люди начинают задавать вопросы типа «а вдруг в этом классе добавятся-убавятся методы» (типичный пример про хэшмеп, в базовый класс которого добавился метод addAll, реализованный как попало), это уже объект внимания совершенно другой по структуре и сложности области. Например, темпоральной логики. И в Java нет никаких встроенных методов решения проблем темпоральной логики.
Есть модель памяти и конкаренси, но это про другое, она отвечает на вопрос, какое в данный момент значение имеет символ, и это не вопрос высокоуровневого дизайна программы, а вопрос разряда «ой, ёпть, чота всё сломалось». У меня есть ощущение, что джава - это скорей о снапшотах, и создании ощущения что мир состоит из снапшотов, чтобы скрыть от глаз страшный реальный мир.
И понимая это, ты приходишь к проблеме конструирования мета-языка поверх Java. Например, правил SOLID (одно из которых говорит, что на каждое мажорное изменение нужно создавать новый класс), или специальных фреймворков (не знаю специальных, наверняка есть, но например в Spring есть своя особенная внутренняя философия на эту тему). Или решать вопрос выходя из границ языка, с помощью пакетного менеджера Linux. Или что-то гибридное, версии бандлов в OSGi. И всё это обмазать системой деплоя, которая реально будет работать в настоящем времени, например, Ansible.
Одного фреймворка будет мало. Даже если это Акка. Фреймворки ложатся на фреймворки, и получается инфраструктура, элементы которой синергетически влияют друг на друга. Таким образом цепочки из десятков классов есть не кривой дизайн, а внешнее отражение внутренне сложной для моделирования области, растянутой в пространстве, времени, конях и людях. Наверное, какая-то очень небольшая часть этих проблем на Haskell это было бы красивее, но это уже другой разговор.
И вот к чему это. Утверждение «наследование - это плохо» - это немного неверно. Наследование не нужно без всего остального. Слепым мастерам, джедаям всех методов класса ArrayList, придется ознакомиться еще с сотнями кусочков, прежде чем осознать свой путь к выходу :3
(Кстати о видеозаписях докладов. Приходите на джава-конференцию JBreak 2017, сможете набить мне морду за эти еретические мысли. Нет, я не докладчик по проблемам ООП, а вот какой-нибудь Бугаенко там точно будет)
Для Ъ: автор сделал несколько качественных обзоров: «лучший роутер 2016», «лучшая электробритва 2016», «лучший арбалет», «лучшая камера для дрона», «iPhone или Android» и т.п., разместил возле рассматриваемых товаров партнёрские ссылки на соответствующие товары в Amazon и органический трафик с поисковых систем принёс ему за 8 месяцев 80000$.
Поделитесь результатми перехода. Стоит ли изучать 2-ой, или продолжать писать на 1-ом? По работе только проекты на Angular1. Google, вроде, к концу весны выкатит Angular3 уже.
Какие вообще плюсы у 2-го Angular вы заметили, после перехода с 1-го?
Немного озадачила сборка hello world angular 2 на 4 Мб Javascript'а, вебпаком, плюс собиралось 14 секунд на ssd - это жуть.
Отказался от webpack в пользу Rollup, в итоге hello world примерно 400 Кб - меня это тоже не устраивает.
Хочу Angular 2 hello world уложить максимум в 100 Кб не сжатых, чтобы сжималось в 20-40 Кб, и чтобы всё это было в одном файле-бандле, возможно такое или Angular2 выпустили специально таким жирным? Как вы собираете Angular приложухи, заморачиваетесь конечным размером или как всегда... по 5 Мб жабоскрипта и в продакшен?
P.S. Про vue и react в курсе, реакт не нравится от слова совсем. Хочу обсудить именно нишу MVC Javascript фреймворков без ФП. К TypeScript, LiveScript отношусь положительно, ещё лучше к Dart.
Перемещено leave из development
Посоветуйте материалов, что посмотреть и что почитать, чтобы понять паттерны (фабрики, синглтон). Не общими фразами, как в целой куче учебников, не официозными определениями из википедии, а с конкретными примерами нормального рабочего кода, с подробным описанием, что там и для чего.
Кроме того интересует работа с DAO и JDBC - пока этот вопрос понимаю весьма поверхностно. Есть пара примеров, разбирал код, но написать сам с нуля пока не в состоянии.
Ну и вообще для начинающего джависта посоветуйте материал на котором можно быстро нахвататься знаний. Имею ярко выраженную проблему в построении алгоритмов, создании классов для решения задач.
Java-тред с двача читал, литературу всю по ссылкам собрал, читаю. Но догоняю не всё.
С советами вроде «java дерьмо», «иди займись чем-нибудь другим» сразу проходим мимо.

Мое рабочее место. Пора идти домой, но лень, там же даже кота нет, на улице темно и холодно (+10).
Настроен Gnome Shell на 3 монитора и 4 спейса:
рабочий чат + рабочий браузер + Evolution.
другие чаты + консоль + нерабочий браузер
виртуалки + виртуалки + еще виртуалки
ничего + офис + еще ничего

В общем то Arch + I3 для работы и жизни в целом. Главной задачей было сделать максимально легкую систему собственно что и вышло.Браузер - chromium. Rss -newsbueur. На Десктопе стандарт:
phpstorm для работы, в нём собственно и вся работа. достаточно удобно выходит. Могу часами не переключатся на браузер. Phpstorm
P.S. А вот обновленный скрин без скролбаров, стало намного лучше! Desktop
Hi All.
Может кто сможет поделится наилучшим опытом для организации playbook для ansible, не много замучился в поисках наиболее оптимального варианта, а плодить кучу playbook как-то не хочется. Дано: inventory.ini
[node01]
kvm-node01.domain
[node02]
kvm-node02.domain
[node03]
kvm-node03.domain
+vars +
+- vms +
+- vm01-config.yml
+- vm02-config.yml
+- vm03-config.yml
+- vm04-config.yml
Пока возникает еще мысль инклудить каждую VM в inventory под каждую ноду, но все таки мне кажется это не оптимальный вариант управления зверинцем.

В общем, я почти собрал домашний ДЦ.
Верхняя полка — blueray плеер (и караоке по совместительству). Ребенок хотел караоке — ребенок получил караоке. Ну и плеер для дисков с мультиками. Планщет — Lenovo, FHD, долго живет от сети. На нем ребенок и супруга играют в игрушки. А еще он пульт от медиацентра. Какого медиацентра? Позже поясню. Справа вверху МФУ. Просто МФУ, струйник, картриджи перезаправляются шприцом. А рядом с ним стоит закрытый бумажкой ASUS RT-AC55. Где провода — там гигабит, где нет проводов — WiFi 802.11n/ac
Середина — телевизор (с нищебродским 3D). На него заведен эзернет, чтобы смотрить киношечки по DLNA (редко пользуюсь, обычно для этого есть следующий пункт).
Справа от ТВ медиацентр — Intel NUC. Он же VPN-шлюз для обхода роскомнадзора (вторая сторона приземлена у немцев) и в сети людей, которым я помогаю со всякими компьютерными штуками. Еще там работает OSPF (у меня случайно получилась достаточно сложна паутина VPN-хостов, и руками там уже не разраутить). NUC по HDMI заведен на ТВ и запущен Kodi. Kodi рулится с планшета (да!!! вот зачем планшет на фото!!!).
Еще правее почти не виден (одни лампочки горят) NAS — NetGear на 4 диска (вставлено только два пока). Он же торрентокачалка. Раздает по http/nfs/cifs/afp - каждый клиент подключается удобным способом. NUC например по NFS, винда с нюка и самсунга (там и винда есть) по SMB.
Понизу — ноутбук служебный, ноутбук личный, ноутбук служебный (с линуксом, да!), иксбокс. Бокс с кинектом, дочь и супруга играют в Kinect Sports Rivals и Dance Central, ребенок еще лупится в DOA5 free demo и Mirror's Edge. А, и еще иксбокс это скайпмашина.
Привет! В чём фишка webpack? Что может webpack, чего не может Gulp? К примеру, мой типичный frontend проект: coffeescript, jade, less.js. Всё это я собираю гульпом так: все less компилируются в один main.min.css, все jade - в соответствующие html, зачастую в виде template для vue.js/angular. Ну а все coffeescript внедряются в один большой файл с глобальными модулями-объектами (обычно около 4-5 главных модуля), и это один жирный coffeescript на лету компилируется в js, добавляется к склеенным библиотекам типа vue.js, затем минифицируется, в итоге получается 100Кб JavaScript'а, после сжатия nginx'ом браузеру выдаётся 20 Кб js, и всё это прекрасно работает. Нафига вообще придумали этот webpack, если много кода пишется не на чистом .js, и удобно ли/нужно ли интегрировать webpack в gulp?
Хочешь стать тролом уровля ЛОР, но не знаешь, как? На реддите идёт тред "доведи питонщика до белого каления в одно предложение". Собрана и вся классика, и много нового. Предлагаю местным новичкам и профессионалам пройти курс повышения квалификации. Можно предлагать свои варианты.
>> Подробности

Собсно с момента предыдущего поста ничего вроде как не изменилось, просто захотелось постануться.
Ну и всё это добро как обычно на https://github.com/neg-serg?tab=repositories
Привет,
я учусь писать приложения на RoR, - возникло несколько вопросов относительно настройки софта под задачу.
В качестве веб-сервера - nginx (ведь альтернатив нет?), а какой выбрать application container - uwsgi или passenger?
Формально uwsgi чаще всего используется для деплоя python приложений - но есть также поддержка ruby и php. http://uwsgi-docs.readthedocs.org/en/latest/Ruby.html
P.S., offtopic: может ли uwsgi быть заменой стандартному php-fpm?
Добрый день, господа.
Вот решил поделиться интересным открытием (не исключаю, что баян). В биосе ноутбука Thinkpad X220 есть флажок «Memory Protection/Execution Prevention», который, если я правильно понял, включает поддержку бита NX (или как он там у Интела называется). Так вот, включение этого флажка увеличивает потребление на 5 ватт (!). В моем случае это 13Вт вместо 7-8Вт.
Вот такая вот энергоёмкая фича.
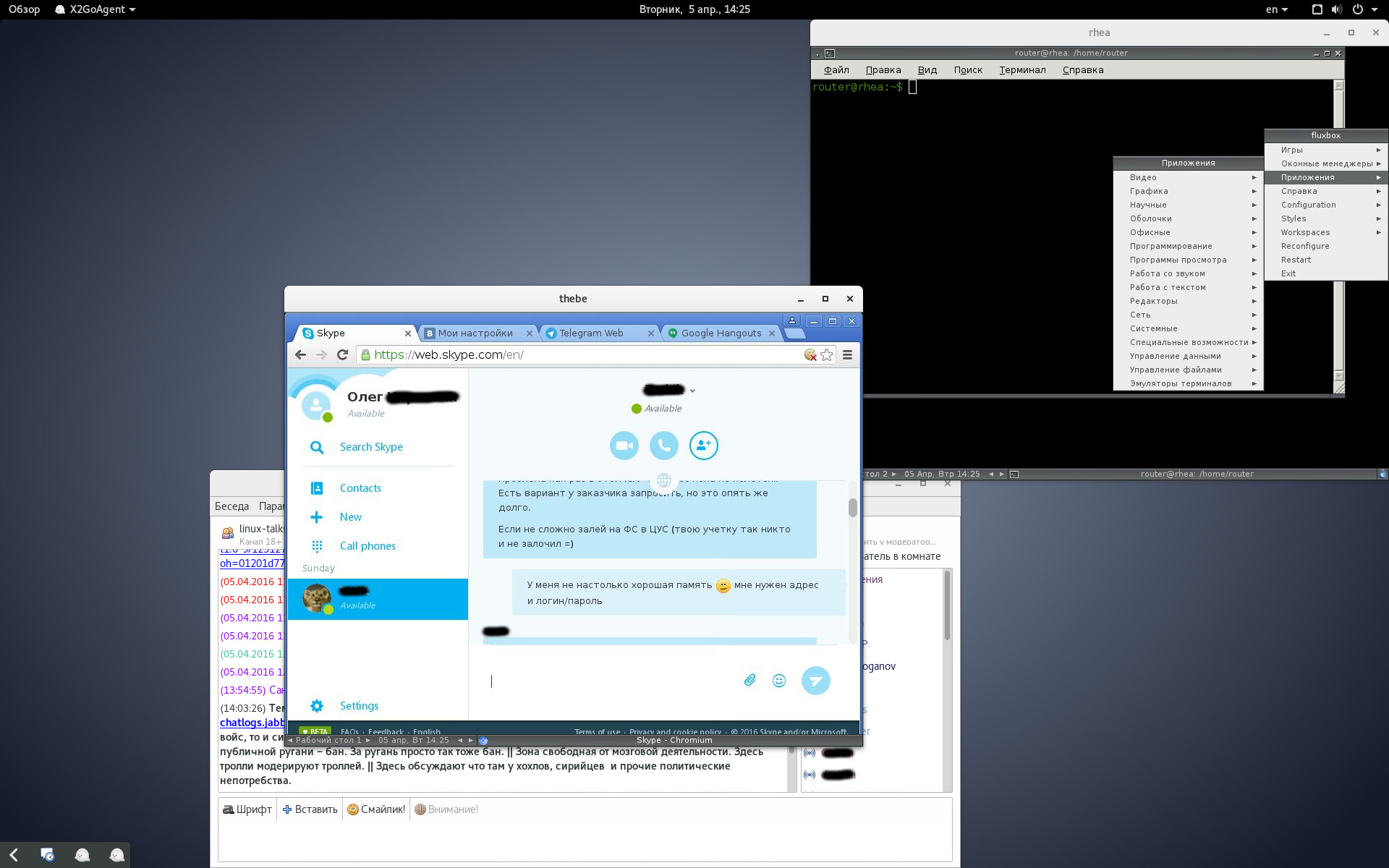
Возвращаясь к вопросам удалённого доступа и бастардов xmpp
IM развелось слишком много, ставить кучу левого ПО на свой ноут или на телефон нет желания. Первая мысль - найти готовый мультипротокольный клиент. Облом. Вторая мысль - найти проект, который будет работать с локально установленными IM-клиентами, выдавая удалённому пользователю общий интерфейс. Опять нет (хотя многие в этом направлении работают).
После того, как я понял что не программист, и реализовать обёртку над IM-клиентами не осилю, решил пойти админским методом - устанавливать IM-клиенты в отдельную ВМ. У большинства IM есть веб-морда, поэтому для начала хватит браузера. При необходимости можно смело ставить родные клиенты, даже если не доверяешь им - максимум что они смогут утащить из пустой ВМ - логи и контакты других IM.
Оставался лишь вопрос удалённого доступа. Google убрал код NeatX в архив. FreeNX после закрытия исходников nomachine nx зачах и работает криво. Зато в Fedora развивается очень интересный проект --x2go.
x2go, как и его предшественники, позволяет подключаться по ssh к удалённой машине. При этом создаётся графическая сессия, не привязанная к реальной консоли. Можно отключаться и подключаться. При этом на обоих сторонах ssh работает агент, который сжимает и кэширует трафик. А события иксов старается обрабатывать локально, не гоняя по сети. Получается высокая скорость и резкая экономия трафика (~ 0.5 КБ/сек в простое вместо ~ МБ/сек). В результате вполне можно работать удалённо, не выбиваясь в лидеры биллинга на рабочем прокси ;) Есть и недостаток - x2go использует старую библиотеку для работы с ssh, поэтому он не будет работать с KEX ecdh-*. Но опять же это решается админскими методами - выносом в изолированный vlan и доступом только из доверенной среды.
То, что нужно. Итак, в ВМ ставим debian в минимальной конфигурации. Зачем ставим x2go из его реп. Остаётся только добавить графический менеджер по вкусу и x11-xkb-utils для переключения раскладки. Я остановился на fluxbox, добавив в ~/.fluxbox/startup
/usr/bin/setxkbmap -layout "us,ru" -option "grp:caps_toggle,grp:alt_shift_toggle,grp:ctrl_shift_toggle,grp_led:scroll" -rules xfree86Если x2go установлен на debian jessie, а подключаться пытаемся из древней ОСи, нужно будет разрешить на сервере ssh использование старого KEX diffie-hellman-group1-sha1 (man sshd_config, /KexAlgorithms).
Итак, на скриншоте ноут с дефолтным gnome shell. Запущены две x2go-сессии к разным ВМ, рядом для примера pidgin. Тема fluxbox - frenzy graphite, утянутая из одноимённого дистрибутива. Вместо привычного firefox запустил google chromium, т.к. он меньше грузит процессор.
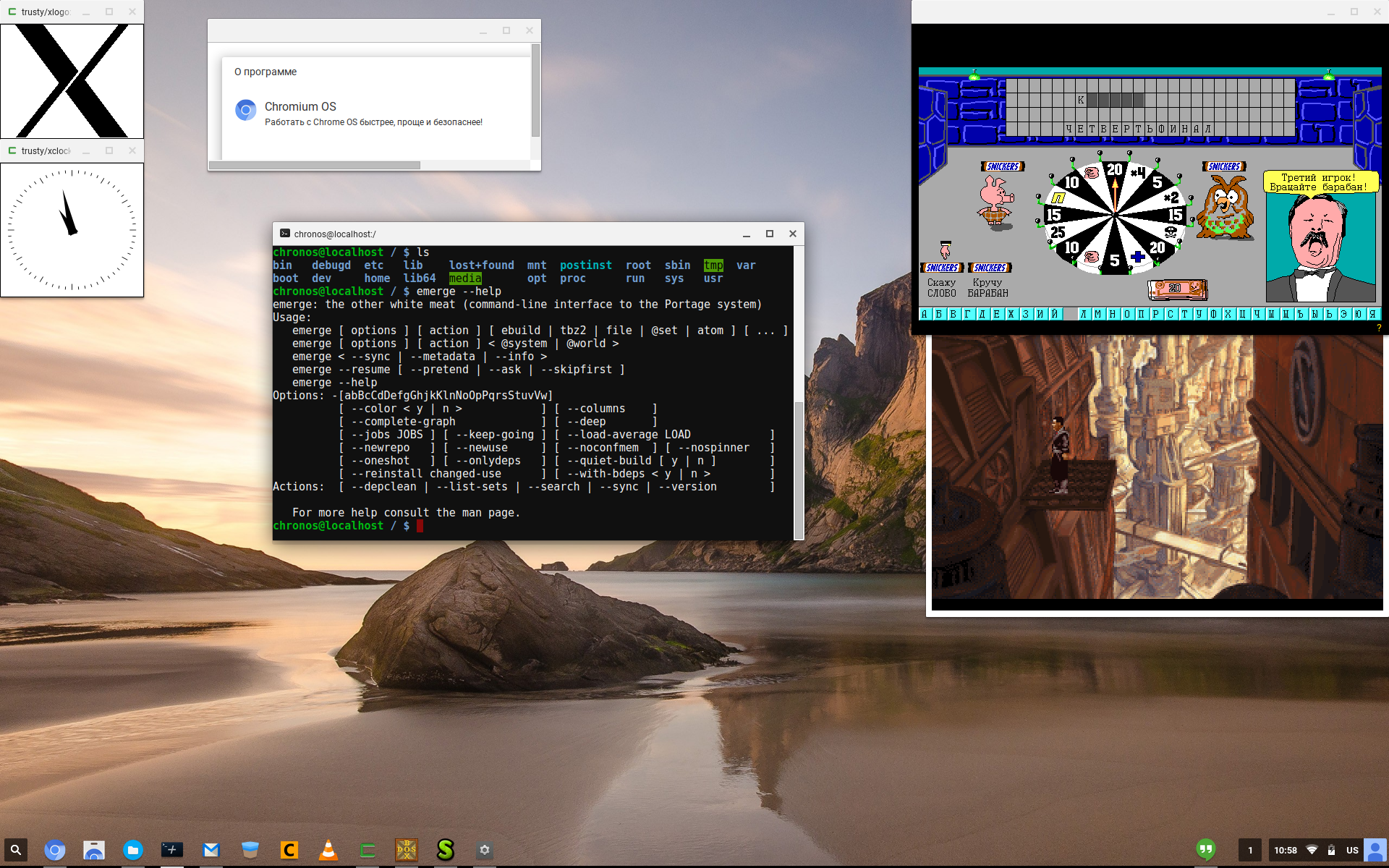
Вполне готово для десктопа, даже проприетарщина в лице flash и кодеков mp3, mp4 и т.п. заработала. Самое то для легкого непринужденного серфинга в нете.
Помимо нативных приложений можно емержить гентушные пакеты, или пускать полноценный Линукс в чруте с помощью crouton.
Т.к. система собирается из исходников, легко запиливаются нужные хотелки, которых не хватает в проприетарной Chrome OS. Тоже самое с адаптацией под железо - необязательно иметь хромбук.
Собирал по этой инструкции https://gist.github.com/gnidorah/8ca4f7db3af38b1622a8

Привет, ЛОР.
Моя неубиваемая машина Aspire M3910 с Fedora Workstation 23 на борту. Ноль расширений, ну разве только User Themes. В общем Fedora радует.
Сообщество Suckless, широко известное своей философией разработки ПО, а также набором программ, среди которых dwm, dmenu, surf, tabbed, st и другие, представило первый установочный образ дистрибутива Stali (static linux).
Проект интересен, прежде всего, множеством нестандартных архитектурных решений, отсутствующих в других дистрибутивах и воплощающих философию suckless на уровне ОС.
Основные отличия:
Разработчики отмечают более высокое быстродействие системы и низкое потребление памяти.
В дополнение к образу доступна пошаговая инструкция по установке.
>>> Подробности
| следующие → |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}