
Возникла необходимость попереводить изображение в текст в большом объёме. Текст русский. Каково сейчас состояние дел с этим в GNU/Linux? Куда посмотреть?
Ответ на:
комментарий
от Burunduk


Ответ на:
комментарий
от fornlr
Ответ на:
комментарий
от Evgueni
Ответ на:
комментарий
от fornlr
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от Evgueni
Ответ на:
комментарий
от Evgueni

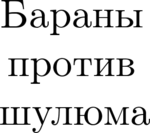
Ответ на:
комментарий
от Evgueni


Вы не можете добавлять комментарии в эту тему. Тема перемещена в архив.
Похожие темы
- Форум Погрешность произведения 4000 8-байтных double (2009)
- Новости Cоздана открытая OCR ;-) (2004)
- Форум [Debian GNU/kFreeBSD] юзабельно ли? (2010)
- Форум Картинки на ЛОРе. Почему так странно сделано? (2019)
- Форум [внезапно приперло][визуализация][c/c++] что можно использовать для двумерной визуализации под линуксом? (2011)
- Форум Калибратор Spyder 4 Express (2018)
- Форум Где хранить изображения: база данных vs файловая система(холивар) (2012)
- Форум Сайт с веб-камерой (2008)
- Форум Ванильный софт, - плюсы и минусы. (2012)
- Новости Вышла первая версия Gnuastro (2016)