Доброго времени. Подскажите пожалуйста глупой женщине: Есть таблица формата /home/users/user/desktop;320;1111-1111-1111-1111-1111song.mp3 нужно по итогу получить таблицу но в третьей колонке удалить несколько символов с хвоста при этом чтоб остальная таблица осталась неизменной /home/users/xander/desktop;320;1111-1111-1111-1111-1111. пробовала и cut и awk но по итогу получаю только одну колонку а надо все
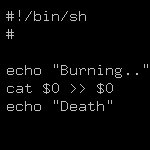
Ответ на:
комментарий
от Kroz
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от Darja
Ответ на:
комментарий
от Darja
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от Yorween
Ответ на:
комментарий
от Kroz
Ответ на:
комментарий
от Kroz
Ответ на:
комментарий
от Kroz
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от Darja
Ответ на:
комментарий
от Yorween
Ответ на:
комментарий
от Darja
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от Darja
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от Yorween
Ответ на:
комментарий
от Darja
Ответ на:
комментарий
от Kroz
Вы не можете добавлять комментарии в эту тему. Тема перемещена в архив.
Похожие темы
- Форум помощь с тестом по Linux (2021)
- Форум Таблица символов (2019)
- Форум Таблица кодов символов (2001)
- Форум Таблица символов для консоли. (2010)
- Форум Что такое таблицы символов ? (2001)
- Форум Как линкер настраивает символы в таблице символов? (2022)
- Форум Удаление всех символов переноса строки в таблице средствами SQL (2015)
- Форум html символы в mysql таблице (2012)
- Форум Таблица символов из .so библиотеки (2007)
- Форум MySQL - удаление из таблиц (2010)