Я придумал такой паттерн (или антипаттерн?). Наверняка он уже существует. Как он называется? Ну и покритикуйте сам подход.
Когда надо хранить историю изменений в какой-то таблице, т.е. не перезаписывать существующие данные, а добавлять новые, можно сделать так.
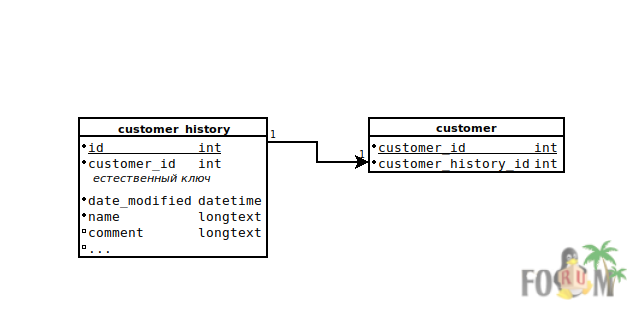
CREATE TABLE customer_history (
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
customer_id INT NOT NULL,
date_modified DATETIME NOT NULL,
name LONGTEXT NOT NULL,
comment LONGTEXT
);
CREATE TABLE customer (
customer_id INT PRIMARY KEY NOT NULL,
customer_history_id INT,
FOREIGN KEY (customer_history_id) REFERENCES customer_history(id),
CONSTRAINT ch_id_unique UNIQUE INDEX (customer_history_id)
);
Получить актуальные данные
SELECT ch.customer_id, ch.name, ch.comment
FROM customer c INNER JOIN customer_history ch ON c.customer_history_id=ch.idINSERT INTO customer_history (customer_id, date_modified, name, comment)
VALUES (1, SYSDATE(), 'Рога и копыта', 'первая версия');
INSERT INTO customer (customer_id, customer_history_id)
VALUES(1, LAST_INSERT_ID());INSERT INTO customer_history (customer_id, date_modified, name, comment)
VALUES (1, SYSDATE(), 'Рога и копыта', 'вторая версия');
UPDATE customer
SET customer_history_id=LAST_INSERT_ID()
WHERE customer_id=1;SELECT *
FROM customer_history
WHERE customer_id=1Linux тут при том, что примеры кода приведены для MySQL.





{kind=link}