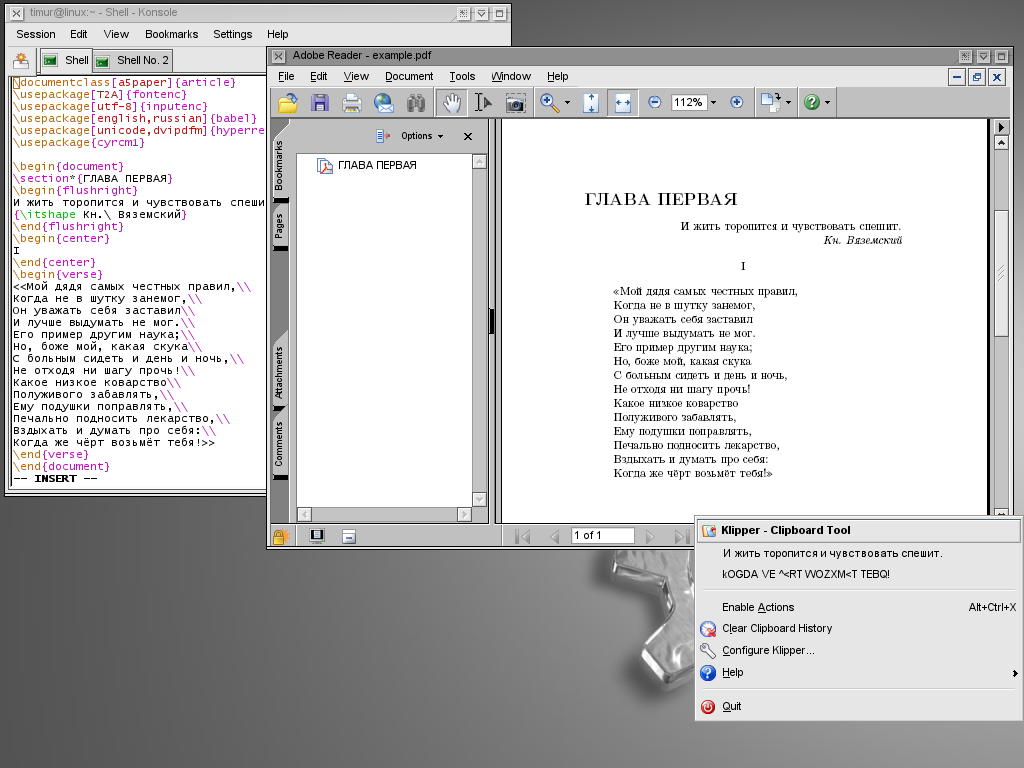
Частенько спрашивают о том как скопировать содержимое PDF'ок,
изготовленных при помощи TeX'а. Результат обычно весьма далёк
от нужного (нижняя строчка klipper'а). Этим страдают и pdftex,
и dvipdfm, и ghostscript (до 8.х). Некоторым нужно ещё и заши-
фровать документ (маниаки). Лучший инструмент для этих целей -
это dvipdfmx. Этот инструмент умеет многое и не страдает недо-
стастом новых версий ghostscript'а, который при шифровании пре-
вращает bookmark'и в неприятность вида \303\352\102\593 и т.д.
PS: Снимок малоинтересный, но почему-то большинство TeX'овых
PDF'ок содержат именно такую каку, и искать по ним практически
невозможно.
LaTeX и русский (UNICODE).