Вышла новая версия Kaitai Struct — языка спецификации произвольных бинарных форматов файлов, пакетов, протоколов и т. д.
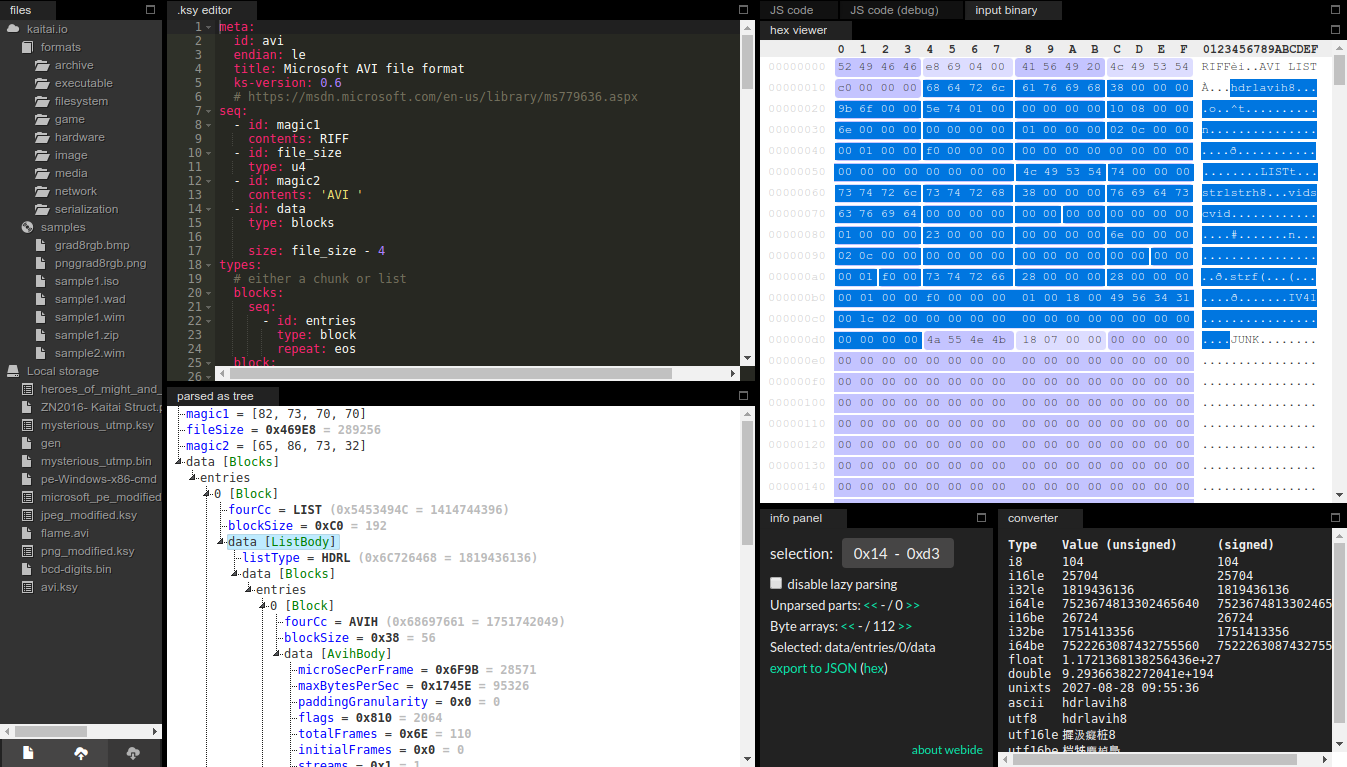
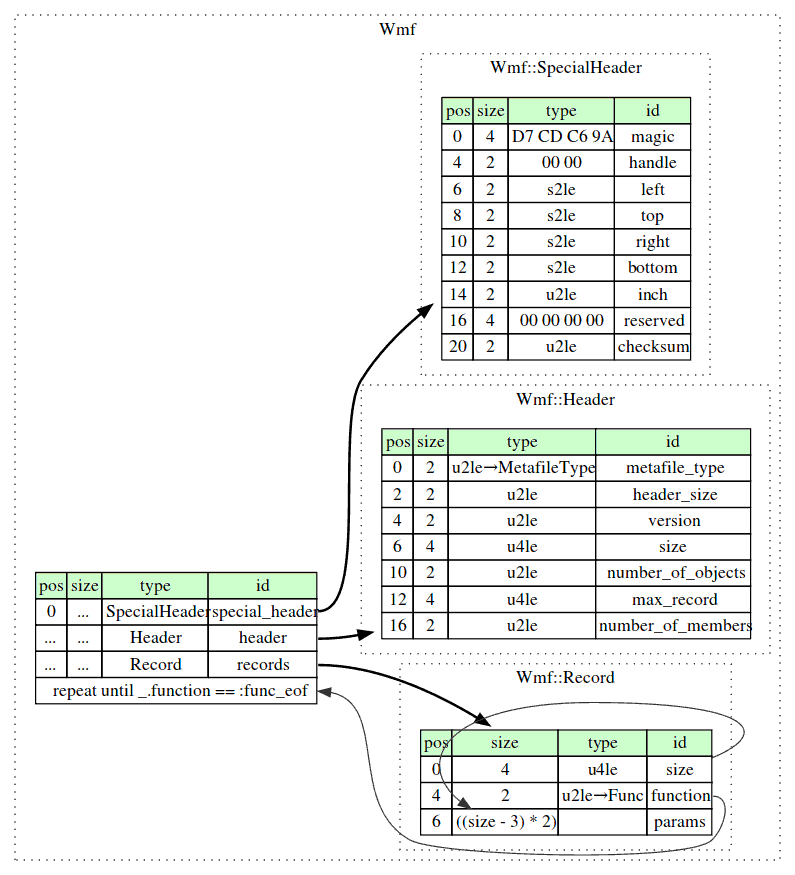
Основная идея проекта в том, что формат бинарного файла описывается один раз на языке .ksy, после чего файлы такого формата можно рассматривать в визуализаторах, получая представление о том, каким байтам соответствуют какие значения элементов формата, сгенерировать человекочитаемую диаграмму формата, а самое главное — сгенерировать готовую библиотеку парсинга такого формата на одном из 8 поддерживаемых целевых языков: C++, C#, Java, JavaScript, Perl, PHP, Python, Ruby.
В новой версии стоит отметить следующие улучшения:
- поддержка побитового чтения (в том числе для парсинга битовых полей, битовых потоков и т.д.) -
type: bXXтеперь позволит прочитать XX бит как число,type: b1прочитает один бит и представит его как boolean - масса возможностей добавить метаинформацию о формате в .ksy: ключ doc на уровне типов, а также ключи title, license, ks-version в meta
- поддержка нестандартных ключей а ля CSS, с минусом в начале; активно используется в Web IDE для задания опций отображения (-webide-representation) и т. д.
- массивные изменения движка вывода типов: enum теперь тоже ресолвится по единым правилам, даже в языках, где таковой поддержки нет нативно (Python, PHP, Perl, JavaScript и т. д.)
- идентификатор id для атрибутов последовательности теперь опционален; если его не задать, будет автоматически присвоен уникальный числовой идентификатор, что удобно для быстрого разбора неизвестных полей в форматах
- поддержка подключения внешних типов (если задать
type: fooи foo не определен в текущем файле, будет сгенерирован корректный import / include в предположении, что тип объявлен во внешнем файле) - возможность писать целочисленные литералы с разделителями (123_456_789 или 0b0101_1111), а также преобразовывать числа в строки с помощью метода to_s
- исправление ошибок, оптимизация генерируемого кода
Релиз приурочен к проходящей в эти выходные конференции FOSDEM 2017. 5 февраля будет представлен доклад о парсинге бинарных media-форматов с помощью Kaitai Struct в рамках Open Media devroom. Для интересующихся, но не имеющих возможности посетить доклад лично, организована онлайн-трансляция видео.
>>> Подробности









{kind=link}
{kind=link}