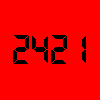Представлена первая тестовая версия проекта CTDB. Целью проекта является создание высокопроизводительного кластера samba хостов. Авторы надеются, что система может масштабироваться до ~ 100 узлов и производительность будет расти линейно.
>>> Подробности