Посмотреть поддерживает ли видеокарта uefi или нет
Форум — Desktop
Как посмотреть поддерживает ли видеокарта nvidia uefi или нет? На винде можно было это сделать через программу GPU-Z и там есть галочка uefi. А на линуксе как?
Как посмотреть поддерживает ли видеокарта nvidia uefi или нет? На винде можно было это сделать через программу GPU-Z и там есть галочка uefi. А на линуксе как?
Всем привет! Захотелось мне решить проблему с доступом заблоченных ресурсов, поднял свой VPS, прикупил Xiaomi AX3000T, прошил его на OpenWRT, настроил Vless, и пошло поехало! Спустя где то 12-15 часов после соединения PPOE (у меня ростелеком) пропадает интернет на секунд 30-40 или чуть больше, я не придал этому значение, так как всякое бывает…Затем через часов 10 история с отвалом WAN порта повторилась! На старом кинетике такой проблемы не было никогда. Стал искать решение проблемы, так толком и не нашел ничего. Взял кабель и воткнул в LAN4 порт роутера, дай думаю проверю как работает инет по кабелю (просто все устройства подключены исключительно по воздуху), за весь день все ок, НО вечером отваливается сеть по лану, захожу в роутер, пишет что соединение по WAN активно, типо все ок, а на компе по кабелю сеть пропала и сама восстановилась через пару минут примерно! Я немного в афиге с этой ситуации…В чем может быть причина отвала LAN и WAN портов? Есть какие идеи как решить эту проблему? Спасибо!
10 апреля состоялся выпуск версии 4.2 библиотеки STC (Smart Template Containers), написанной на языке C (C99) и распространяемой по лицензии MIT.
Изменения:
Coroutines и сопутствующая документация;crand.h. Предыдущий crandom.h объявлен устаревшим;c_const_cast;c_foreach_r переименован в c_foreach_rv;c_flt_count переименован в c_flt_counter;c_flt_last переименован в c_flt_getcount;c_ARRAYLEN переименован в c_arraylen;c_ARGSV();c_PAIR.По утверждениям разработчиков, STC — это современная быстрая типо-безопасная небольшая библиотека контейнеров и алгоритмов для языка Си (стандарт C99). Библиотека создана под влиянием C++ STL, а также некоторых идей из Rust и Python.
Пример использования:
#define i_extern // include external cstr, utf8, cregex functions implementation.
#include <stc/cregex.h>
int main() {
const char* input = "start date is 2023-03-01, end date 2025-12-31.";
const char* pattern = "\\b(\\d\\d\\d\\d)-(\\d\\d)-(\\d\\d)\\b";
cregex re = cregex_from(pattern);
// Lets find the first date in the string:
csview match[4]; // full-match, year, month, date.
if (cregex_find(&re, input, match) == CREG_OK)
printf("Found date: %.*s\n", c_SV(match[0]));
else
printf("Could not find any date\n");
// Lets change all dates into US date format MM/DD/YYYY:
cstr us_input = cregex_replace(&re, input, "$2/$3/$1");
printf("%s\n", cstr_str(&us_input));
// Free allocated data
cstr_drop(&us_input);
cregex_drop(&re);
}
>>> Подробности
Посоветуйте библиотеку на плюсах для клиента REST API с поддержкой https. Пытался сделать на asio но запутался в возне с сертификатами, хотелось бы найти либу которая бы сама всё это делала.
История эта началась с рутинного действия. По моей просьбе пользователь Windows 7 загрузил на свой компьютер большие файлы (у меня не было стабильного интернета). Большие файлы представляли собой «нарезку» образов под лимиты ФС FAT32. Человек скопировал файлы на мою флешку.
Поскольку я знаю, как обычные люди пользуются флешками на компьютерах с «виндой», то флешку ждала fsck. Первые строки вывода команды вроде бы подтверждали мои ожидания…
There are differences between boot sector and its backup.
fsck слегка призадумалась и после некоторой паузы выдала (подобных строк было много; для иллюстрации я оставил одну строчку)
[manjaro manjaro]# fsck /dev/sdb1
fsck from util-linux 2.37.4
fsck.fat 4.2 (2021-01-31)
...
/path/file.img
File size is 4294963200 bytes, cluster chain length is 0 bytes.
Truncating file to 0 bytes.
...
Такого я ещё не видел.
Первая мысль: флешку выдернули не просто без выполнения команды «Извлечь», но даже дописать файлы на флешку не дали. Я соглашаюсь с предложенным fsck лечением. Получаю в итоге файлы нулевой длины.
Дальше я напрашиваюсь в гости к моему добровольному помощнику – файлы-то мне забрать необходимо. Выполняю весь процесс самостоятельно: копирую файлы, делаю hash файлов, безопасно извлекаю флешку.
Подключаю флешку к своему ноутбуку. Для fsck ничего не изменилось
...
/path/file.img
File size is 4294963200 bytes, cluster chain length is 0 bytes.
Truncating file to 0 bytes.
...
В этот раз я от «лечения» флешки отказываюсь. Монтирую флешку в ro. Файлы читаются полностью. Хеш «оригиналов» совпадает с хешами файлов на флешке.
Где баг?
FAT32fsck![]() Gonzo вот так выглядит моё «очевидное-невероятное» :)
Gonzo вот так выглядит моё «очевидное-невероятное» :)
Сперва я думал создать вопрос в General.
После того как я убедился в целостности файлов эта история больше, чем на Talks «не тянет».
Итог: «баг» ожидаемо оказался в fsck.fat. Спасибо ![]() i-rinat: «пришёл и расставил все точки, где надо» :). В
i-rinat: «пришёл и расставил все точки, где надо» :). В AUR есть пакет с фиксом.
Доброго времени суток. Не так давно я лишился возможности оплачивать сервер в scaleway. В связи с чем ищу ему замену. Я ищу себе сервер под свой инстанс NextCloud`а. 2 гига - 2 ядра и и для экономии денег медленное хранилище на обычных дисках а не новомодных nvme. Но размером от 100Гб. Так же требованием к хостингу является возможность оплаты картой МИР и цена не более 900Руб/мес
Так же планирую держать на сервере выход OpenVPN для личных нужд. В связи с чем интересует вопрос. А обязаны ли хостинги соблюдать требование ограничивать доступ к определённым ресурсам на выделенных серверах? Или искать сервер нужно расположенный в одной из евро стран?
Мне интересными показались вот такие предложения:
ispserver.ru Но не могу разобраться в каком из 3х их датацетров будет размещаться сервер.
https://justhost.ru/ Но при выборе сервера за пределами России, цена драматически вырастает за допустимые для меня размеры.
Может у кого то из ЛОРовцев есть на примете хостинг отвечающий моим запросам?
Лаборатория эволюционной геномики Факультета биоинженерии и биоинформатики МГУ им. М.В. Ломоносова – одна из сильнейших в области биоинформатики в России. Руководит лабораторией профессор Алексей Кондрашов.
Наш основной рабочий инструмент – вычислительный кластер «Макарьич», который мы и предлагаем вам взять под свою опеку. Это значит, что свободы действий будет много, но и вся ответственность за его работу ляжет на вас.
Что придется делать? Следить за состоянием кластера и особенно основной файловой системой Lustre, собирать системное и научное ПО по запросам пользователей, планировать развитие и закупки для кластера и, конечно, вести документацию.
Работают на кластере самые разные люди – от студентов до докторов наук; все они пылают страстью к научным открытиям, но ИТ-квалификация у них варьирует в широких пределах. Так что в сложных случаях надо будет помогать им со сборкой ПО и подсказывать оптимальный режим запуска задач с учетом особенностей кластера. В отдельных случаях намекать особенно увлеченным ученым на непропорционально большое количество ресурсов используемых ресурсов.
Формальные обязанности:
Требования:
Однозначным плюсом будут:
Условия:
Так как кластер - неотъемлемая часть жизни большинства сотрудников лаборатории, то вы легко вольетесь в научное сообщество и сможете, при желании, посещать конференции вместе с коллегами. Кроме того, если у вас есть собственный исследовательский проект (необязательно в области биоинформатики), вы сможете использовать вычислительные ресурсы кластера (в пределах разумного) для его выполнения.
График работы:
Большую часть времени можно работать удаленно, но как минимум 1 раз в неделю необходимо посещение лабораторного семинара для личного общения с сотрудниками. Желательно, чтобы в аварийной ситуации, вы могли оказаться возле кластера в течение часа. Кластер физически расположен в здании Факультета биоинженерии и биоинформатики МГУ им. М. В. Ломоносова (м. Университет)
Зарплата:
120 000 рублей (испытательный срок - 80 т.р)
Контакты:
Писать по поводу вакансии можно мне:
Артур Залевский
aozalevsky@fbb.msu.ru
Telegram: @aozalevsky
Собственно сабж. Третий андрофон. В первый раз ставил из него судоку. Во второй: блокнот. В этот раз: «Транзистор» для прослушивания радио.
А кто чем ещё пользуется?
Тег «угадай автора по заголовку».
Q: Зачем?
A: Ради эксперимента, повысится комфорт пользования терминалом или нет.
Q: Причем тут Rust?
A: Ни при чем, но из-за нативности и отсутствия GC на нем толпа людей побежала переписывать что ни попадя. С таким же успехом можно было бы и npm install, но тормозило бы. Ближе opam install или go get
Теперь мой терминал по истине свистит и пердит. Даю список если кому надо.
alacritty - GPU ускоренный терминал.
alias cat=bat- cat с хорошей подсветкой синтаксиса и нумерацией строк и пейджером.
broot - навигатор по каталогам, который одновременно показывает дерево, но адекватно себя ведет с громадными каталогами, показывая их по чуть-чуть.
dust - утилита для исследования места занимаемого каталогами, сортирует деревья файлов начиная с самых больших каталогов.
alias ls="exa -l --group-directories-first" ls с хорошими дефолтами, tree встроено.
rip Утилита для удаления файлов с разными удобными фичами и восстановлением
hors "How do I parse float in javascript?" - находит короткий ответ в интернетах и отвечает. Чуть лучше работает чем оригинал - howdoi.
mdcat - cat для Markdown, для отображения удобочитаемой формы документа. Ссылки делает сносками.
alias grep=rg - очень быстрый и удобный grep
starship - shell command prompt, показывает кучу полезной информации в зависимости от контекста, например git branch если в репозитории, версии софта и ЯП если в каталогах с сорцами, hostname если зайти по ssh.
tokei - сборщик статистики по ЯП и строкам кода в деревьях исходников.
hyperfine - бенчмарк утилита, time на стероидах.
tldr- сокращенная версия man, показывает как чем пользоваться в примерах, а не выдавая полную справку. Страницы поддерживаются сообществом для громадного количества утилит. Изначальный проект - https://tldr.sh/
topgrade - универсальная утилита обновления. При запуске пытается обновить все что видит - системные пакеты, vim пакеты и так далее.
runiq - быстрый sort | uniq с разными алгоритмами внутри.
fd - быстрый и удобный find, удобно чтобы не вспоминать заковыристые ключи
fselect - поисковик файлов с SQL-like языком запросов
sd - как sed, только интуитивный
i3status-rs - Сразу i3status+i3blocks. Плюс батарейки к i3blocks, которые как я понял автор решил убрать.
onefetch - Вроде neofetch, но для сорцов. Просто запустите эту штуку с корня любого git репа, клонированого локально
wasmtime - JIT runtime для WASI стандарта. Пускалка WebAssembly приложений.
scriptisto - «shebang-интерпретатор» для компилируемых языков, прозрачно собирает и кеширует нативные сборки кода
Что не зашло совсем
Все вышеперечисленое ставится через cargo install <package_name> (кроме alacritty), название смотрите на страницах. Сам cargo и Rust ставятся через
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
P.S. Призываю остальных взять ЯП вашей секты и поставить такой эксперимент и отписаться. Да-да, расскажите как вы пользовались ls на Java. Пользователей emacs прошу не беспокоить
Для обычных абзацев это нормально: оставить на предыдущей странице первые две строки, а остальной текст перенести на следующую. В случае же кусков кода и прочего, для чего использую Verbatim, это выглядит плохо. Можно как-нибудь запретить? Чтобы, например, оставалось не меньше 4 строк. А если не получается, то пусть переносит блок на следующую страницу целиком, оставляя на предыдущей пустое место.
Видел у fancyvrb опцию samepage, но она не подходит — сама возможность разорвать блок мне нужна (плюс, некоторые блоки просто не поместятся на одну страницу).
Возможно, баян, но почему я раньше не знал?? Раньше гуглил, а только что обнаружил вот это http://detexify.kirelabs.org/classify.html Возможно, кому-то окажется полезным.
Надо распечатать небольшой текст. Ни формул, ни таблиц, только примечания.
Но «просто распечатать» скучно. Можно ли с помощью латеха минимальными усилиями превратить текст во что-то подобное: https://upload.wikimedia.org/wikipedia/commons/1/1d/Fraktur.png ? Ну то есть включить все возможные «украшения», до которых додумывались издатели книг. Для моего документа такой вид не просто уместен, а даже желателен. Текст на английском.
И вообще в латехе ли это надо делать? (опыта с ним не имею)
Есть ли смысл использовать для численных расчетов python (методы конечных элементов, математические расчеты, много циклов, большие данные)?
Или лучше использовать c++? Насколько медленнее код получается?
Плюсы питона:
Минусы питона:
Дал прогу на c++ одному, от так и не смог его осилить :(
Поделитесь историей успеха.
Лаборатория эволюционной геномики Факультета биоинженерии и биоинформатики МГУ им. М.В. Ломоносова – одна из сильнейших в области биоинформатики в России – ищет администратора вычислительного кластера. Руководит лабораторией профессор Алексей Кондрашов.
Наш основной рабочий инструмент – вычислительный кластер «Макарьич», который мы и предлагаем вам взять под свою опеку. Это значит, что свободы действий будет много, но и вся ответственность за его работу ляжет на вас.
Что придется делать? Следить за состоянием кластера и особенно основной файловой системой Lustre, собирать системное и научное ПО по запросам пользователей, планировать развитие и закупки для кластера и, конечно, вести документацию.
Работают на кластере самые разные люди – от студентов до докторов наук; все они пылают страстью к научным открытиям, но ИТ-квалификация у них варьирует в широких пределах. Так что в сложных случаях надо будет помогать им со сборкой ПО и подсказывать оптимальный режим запуска задач с учетом особенностей кластера. В отдельных случаях намекать особенно увлеченным ученым на непропорционально большое количество ресурсов используемых ресурсов.
Обязанности:
Так как кластер - неотъемлемая часть жизни большинства сотрудников лаборатории, то вы легко вольетесь в научное сообщество и сможете, при желании, посещать конференции вместе с коллегами. Кроме того, если у вас есть собственный исследовательский проект (необязательно в области биоинформатики), вы сможете использовать вычислительные ресурсы кластера (в пределах разумного) для его выполнения.
Кластер физически расположен в здании Факультета биоинженерии и биоинформатики МГУ им. М. В. Ломоносова (м. Университет)
Зарплата: 100 000 рублей (на руки)
Писать по поводу вакансии можно мне:
Артур Залевский
aozalevsky@fbb.msu.ru
Telegram: @aozalevsky
и моему коллеге:
Дмитрий Виноградов
dimavin@bioinf.fbb.msu.ru
Telegram: @dimavin
Есть несколько библиотек в разных директориях, которые собираются с помощью add_library
Как можно их объединить в одну цель: ну т.е. типа make tests и все мои библиотеки собрались?
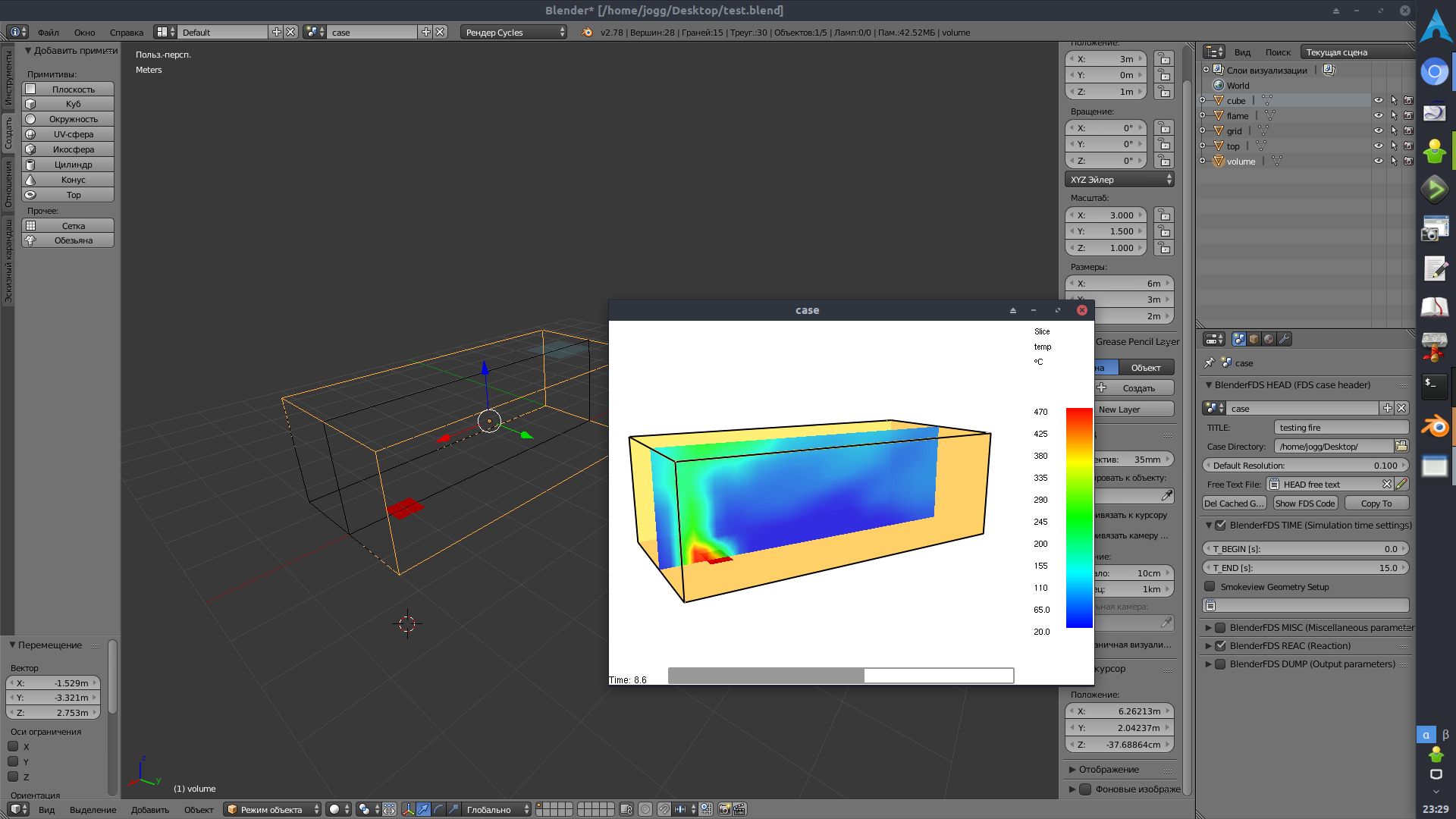
В рамках изучения FDS, наткнулся на очень интересный проект BlenderFDS — создание сценариев для FDS с помощью Blender. К слову, вполне работоспособная альтернатива PyroSim (который, впрочем, не так уж дорого стоит, с точки зрения крупного предприятия).

Текущая версия клиента Skype 4.3 для Linux и все старые версии клиента не будут работать с 1 марта 2017 года. Сделано это в связи с тем, что Microsoft отказывается от старого peer-to-peer протокола, и полностью переходит на централизованную схему работы.
Всем Linux пользователям предложено перейти на alpha-версию нового приложения Skype, либо использовать веб-клиент. Новое приложение построено с использованием платформы Electron и является надстройкой над Chromium и Node.js.
>>> Подробности
Нужно (1) записать результат выполнения обычной команды (скажем, hostname) в переменную. А затем, (2) эту переменную записать в template.
Для этого я делаю:
1. В defaults/main.yml:
test: "$(hostname)"
2. В templates/test.conf.j2
myhostname={{ test }}
3. В tasks/test.yml:
---
- name: test variable in template
template:
src: templates/test.conf.j2
dest: /root/test.conf
owner: root
group: root
mode: 644
Таким образом, на каждой машине образовывается файл с её хостнеймом.
Вопрос: как это правильно делать в ansible? Почему ответ не так очевиден (из мануалов), ведь это, наверняка, распространненая задача?
Есть у меня один проект - генератор поточных парсеров текста, размеченного конструкциями вида:
\macro{arg1}{arg2}
база построена на системе событий: обработчик идёт по тексту, выводит этот текст в свой результирующий поток. Как только ловит подобное macro - ищет его в таблице определений, оттуда он достаёт инфу о процедурах которые нужно проделать когда ловится такая макра, процедуре при начале считывании первого аргумента, окончании считывания первого аргумента и так далее. В процедурах доступны функции управления выводом текста, управления стеком окружений таких макров, таблицей определений - можно переопределять макры, доопределять, в том числе только в рамках определённого окружения отдельного макра.
Это база, на ней строится и всякий сахар типа работы с аргументами как со строками, заглушка вывода, механизм latex-окружений - конструкций вида:
\begin{env}{arg1}
text bla bla bla
\end{env}
Проект пишу на CL. Одна из причин создания проекта - препроцессинг tex-кода, нежелание учить тонкости расширения TeX его же средствами, представления о этих средствах как о довольно убогих инструментах. Вторая - мне нравятся подобные языки разметки и не понимаю почему они не выходят за рамки TeX-экосистемы, когда как они вполне могут представлять альтернативу всяким XML.
На данный момент уже есть прототип, в котором реализовано большинство намеченных функций. Причём этот прототип у меня валяется уже год без развития, не смотря на некоторые случаи практического применения. Недавно я возобновил работы над проектом.
Конечно у проекта есть проблемы. Это отсутствие документации, без которой я не вижу смысла публиковать код под свободной лицензией (а я намерен это сделать). Это проблемы с терминологией - в коде используются довольно неадекватные термины. Для этого я практически закончил писанину о концепции, краткую выжимку которой я описал выше и на основе которой буду писать документацию. Вот действительно как назвать этот проект? Как назвать семейство таких языков, на обработку которых нацелен проект?
Свежим взглядом прочитав код, планирую довольно глубокое перелопачивание кода. Для этого сейчас пишу тесты, чтобы тестировать хотя бы уже реализованные возможности.
Есть вот похожий по мотивации проект plump-tex.
В CentOS 7 съезжает системное время. Вот сейчас, например, показывает «14:34:30», хотя сейчас «10:57:30». (время Московское)
Ручная синхронизация с сервером, командой «ntpdate 0.ru.pool.ntp.org» правит часы, но после перезагрузки они опять съезжают.
Таймзона вроде правильно выставлена, на Москву:
$ timedatectl
Local time: Вс 2016-12-04 14:34:30 MSK
Universal time: Вс 2016-12-04 11:34:30 UTC
RTC time: Вс 2016-12-04 11:34:29
Time zone: Europe/Moscow (MSK, +0300)
NTP enabled: n/a
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
$ ls -l /etc/localtime
lrwxrwxrwx 1 root root 35 дек 1 13:11 /etc/localtime -> ../usr/share/zoneinfo/Europe/Moscow| следующие → |
{kind=link}