LRDIMM DDR4 128Гб на планку от Гнусмуса. LRDIMM - новый FB-DIMM?
http://habrahabr.ru/company/hostkey/blog/272063/ http://habrahabr.ru/post/218673/
Почти полтора года назад выпустили LRDIMM DDR4 128Гб планку, сейчас гнусмус сделал более дешевую. Кто-нибудь тут использует DDR4 или LRDIMM DDR4? В чём смысл? Можно больше памяти за дешево воткнуть? Насколько я понимаю, производительность как была на уровне днища банного (DDR3), так и осталась.
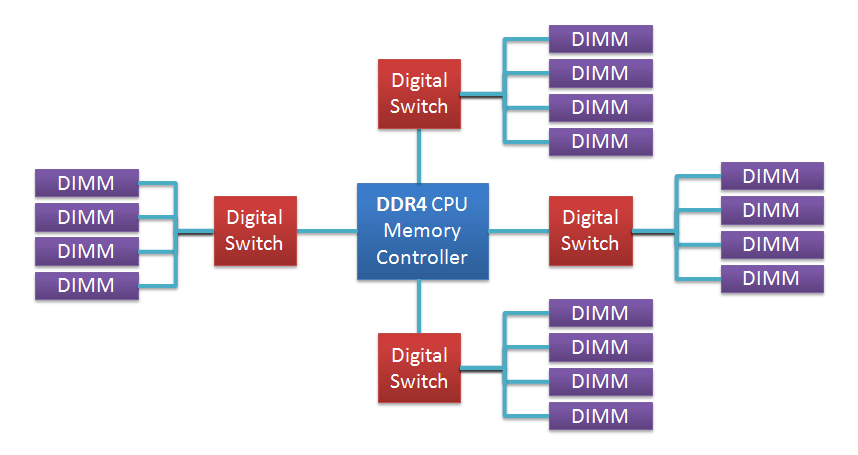
И да: ничего не напоминает новая схема подключения памяти?.источник
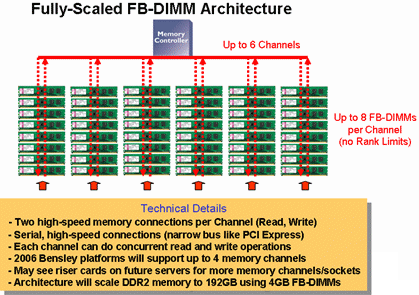
LRDIMM DDR4 - приемник FB-DIMM? http://2.bp.blogspot.com/-rmWkUOY1-kY/UBP4yXuRrmI/AAAAAAAAACQ/RC6amDvGdjM/s16... http://www.hardwaresecrets.com/wp-content/uploads/266_011.jpg
{kind=link}
{kind=link}
{kind=link}