Как скайп передает сетевой трафик между клиентами за NAT-ом?
Форум — Development
M$ Скайп вроде P2P. Как реализован сабж в нем?
Какой еще существует софт с аналогичной функциональностью?
Меня интересует только сетевая часть.
M$ Скайп вроде P2P. Как реализован сабж в нем?
Какой еще существует софт с аналогичной функциональностью?
Меня интересует только сетевая часть.
Вот вся инфа, которую догадался предоставить.
# zcat /proc/config.gz | grep HIBER
CONFIG_ARCH_HIBERNATION_POSSIBLE=y
CONFIG_ARCH_HIBERNATION_HEADER=y
CONFIG_HIBERNATE_CALLBACKS=y
CONFIG_HIBERNATION=y
# zcat /proc/config.gz | grep SUSP
CONFIG_ARCH_SUSPEND_POSSIBLE=y
CONFIG_OLD_SIGSUSPEND3=y
CONFIG_SUSPEND=y
CONFIG_SUSPEND_FREEZER=y
# CONFIG_SUSPEND_SKIP_SYNC is not set
# CONFIG_BT_HCIBTUSB_AUTOSUSPEND is not set
# cat /proc/cmdline
BOOT_IMAGE=/kernel-genkernel-x86_64-4.16.2-gentoo root=/dev/mapper/lvm-root ro crypt_root=UUID=74f4955f-b422-4abe-8bcf-8329919222aa dolvm real_root=UUID=bbd59fba-ed35-4289-86a1-5c16106f2317 real_resume=UUID=a6401d1c-1769-45b0-b582-8b16e238f6bf
# lsblk -o name,type,mountpoint
NAME TYPE MOUNTPOINT
sda disk
├─sda1 part /boot/efi
├─sda2 part
│ └─cboot crypt /boot
└─sda3 part
└─root crypt
├─lvm-swap lvm [SWAP]
├─lvm-root lvm /
└─lvm-home lvm /home
sr0 rom
Ядро собирал генкернелом. Как видно, своп располагается в довольно труднодоступном месте.
Что я понял из процесса загрузки: сначала грубом грузится ядро, чё-то там своё делает, потом передаёт руль initramfs, который просит у меня пароль от рута, разблокирует его и получает-таки доступ к заветному свопу, на который s2disk в прошлый раз уложил (кстати, вроде бы вполне успешно) систему спать.
Судя по всему, initramfs свою функцию выполняет, т.к. после ввода пароля я замечаю в летящем вверх логе что-то про real_resume, обнаруженный на /dev/dm-1, а ещё убеждаюсь, что initramfs успел записать этот самый /dev/dm-1 в /sys/power/resume (в чём я убеждаюсь чуть позже, после провала resume):
# cat /sys/power/resume
253:1
# file /dev/dm-1
/dev/dm-1: block special (253/1)
Я точно не знаю, что здесь не так и почему лыжи не едут, но у меня есть несколько гипотез:
1) «253:1» - не совсем тот формат, который нужен в новых модных ядрах линя (у меня 4.16.2, если что)
2) запись в /sys/power/resume происходит невовремя (например, когда примонтирован настоящий рут, или, наоборот, не примонтирован)
3) просто кривые конфиги ядра
Короче, если у кого есть идеи, куда двигаться, или если кто такую систему уже заставлял выходить из гибернации, то прошу поделиться.
Я ещё слышал, что существуют разные виды саспенда, типа TuxOnIce и swsusp, нифига не понял, чем они отличаются, и пришёл к выводу, что у меня swsusp, исходя из структуры каталогов на /sys. Если это не так, то я вообще не в ту сторону думаю, тогда проясните мне ситуацию.
Я тут задумался, все мы знаем РМС(16 марта его др, долгих лет жизни ему, не забудьте съесть яблоко за его здоровье! А еще 16 марта Крым вернулся в состав России), но не все мы так уважаем его идеологию, вообще движение за свободный интернет, за свободный софт и за право обладать своим компьютером, не будучи тупым юзером которому дали попользоваться проприетарным терминалом по ИХ правилам за СВОИ же еще деньги.
Но братцы, ответьте мне, те кто на вопрос «а есть ли что нибудь под лицензией ГПЛ» выпадают чем-то в духе «Тебе зачем это?» или «У тебя еще из ушей тот ГПЛ не течёт?» или «Какая тебе польза от того что оно НЕпроприетарное?», зачем вы так? мы ведь здесь всё за свободу, за открытость и за новый светлый мир.
Неужели вы не понимаете, что чем больше будет софта под лицензией GPL, тем свободнее будет вообще ВСЁ, тем скорее мы избавимся от различных опухолей вроде м$ и им подобных метастаз, неужели вы не понимаете, что нужно требовать, нужно «голосовать» своим юзкейсом и использованием за ГПЛ иначе вся эта гну\линукс заваруха кончится ничем, иначе вы просто тупые приспособленцы и не идейные люди, вы убьете всю идею СПО.
Мы не должны забывать, что мы все в одной команде и должны действовать совместно и целенаправленно, двигаться к свободному миру, иначе мы его потеряем, чем большая компьютеризация в мире с преобладающим проприетарным ПО, тем хуже всем нам простым людям будет, тем ужаснее будет наше будущее и будущее людей после нас!
ВЫБИРАЙ GPL!
Common Lisp разрабатывался и используется в предположении, что пользователь программы — программист. Поэтому из языка намеренно исключены сложные для понимания конструкции (пользователь не обязательно квалифицированный программист), поэтому в языке мощнейший отладчик, позволяющий без остановки программы переопределять функции и вообще делать что угодно. Но из-за этого документация по большей части библиотек Common Lisp существует только в виде docstring и комментариев в коде (некоторые вообще считают, что код сам себе документация). Из-за этого обработка ошибок почти всегда оставляется на отладчик (главное сделать рестарт «перезапустить с последней итерации», а там пользователь сам разберётся). Из-за этого в программе проверяется только happy path (пользователь ведь «тоже программист»).
Racket разрабатывался и используется в предположении, что пользователь программы не программист, а задача разработчика написать программу так, чтобы она корректно работала при любых входных данных (если данные некорректны, то сообщала об этом в том месте, где данные были введены). Поэтому в языке эффективная библиотека для написания тестов, система контрактов на уровне модулей, макимально широкий спектр инструментов программирования (разработчик должен быть профессионалом!). Также реализована идея инкапсуляции: считается, что пользователь модуля не должен знать особенности реализации и, более того, не может в своём коде изменить функцию чужого модуля если это явно не разрешено разработчиком того модуля. Исходный код разумеется доступен, но его не требуется смотреть, чтобы использовать модуль. Достаточно документации. Поэтому реализована мощнейшая система документировния Scribble, а при реализации макроса есть возможность обеспечить указание на ошибки в коде, предоставленном макросу пользователем, не показывая потроха макроса.
И поэтому в Racket нет CLOS (есть как минимум две реализации, но не используются) - провоцирует заплаточное программирование (monkey patching), поэтому отладчик намеренно ограничен (если ты отлаживаешь программу, значит ты не знаешь как она должна работать!), поэтому нет разработки в образе (image based) - она провоцирует разработку через отладку (а значит непонимание программы и проверку только happy path).
Таким образом, Racket и Common Lisp несмотря на внешнее сходство являются очень разными языками. И я рекомендую писать на Racket, если только конечными пользователями программы не являются исключительно программисты на Common Lisp.
Взято с http://racket-lang.blog.ru/#post214726099
Хотелось бы знать, что по этому поводу думают пользователи ЛОРа. А также, мне кажется, что для Java и C++ будет где-то такая же разница.
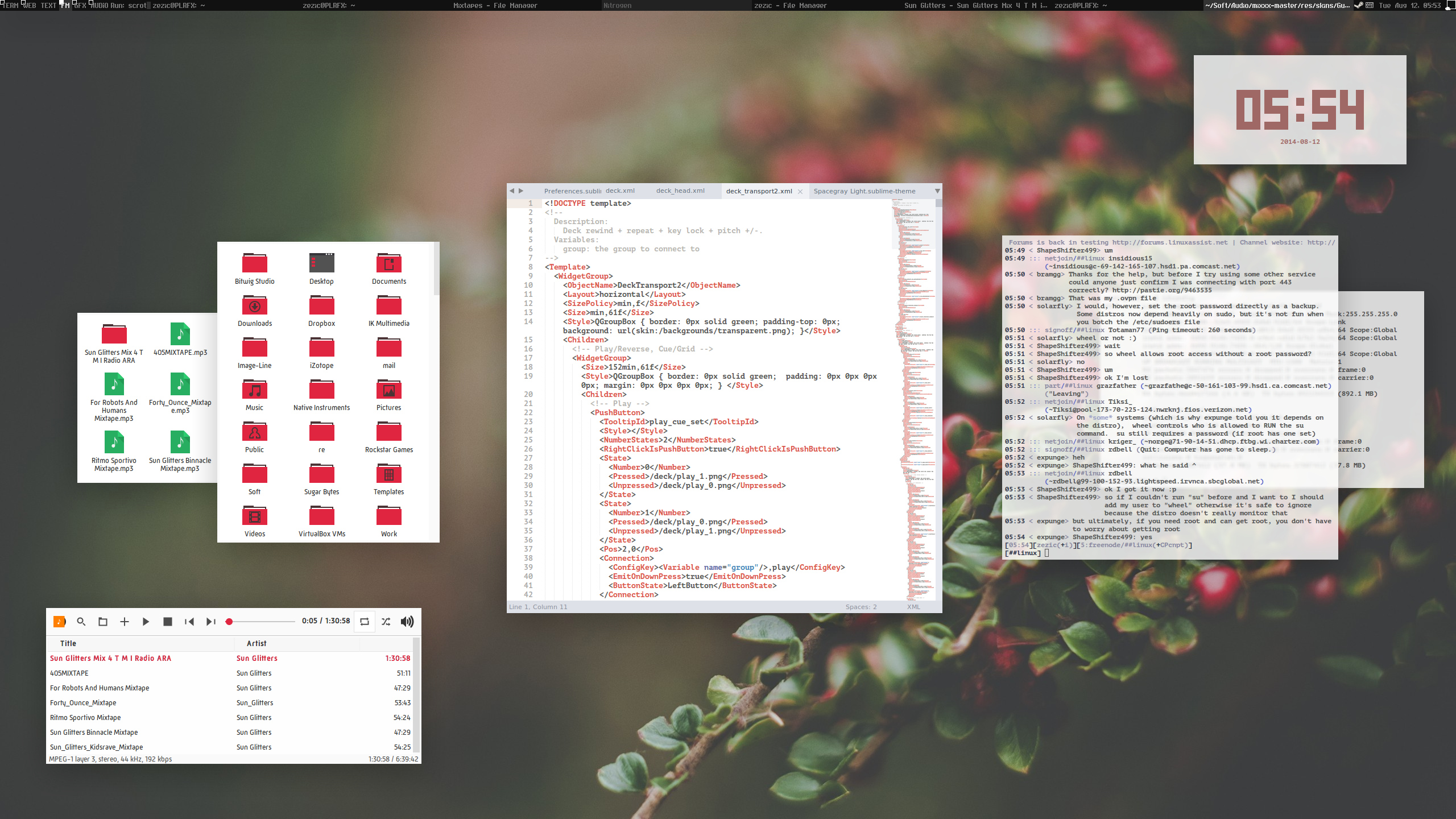
GTK: Iris Light
Обои: Berries (источник не найден)
Иконки: перекрашенные Flattr
Шрифты: Russia и PT Mono
Привет, мы в компании Эрливидео ( https://erlyvideo.ru/ ) помимо серверного софта для трансляций телевидения и массового видеонаблюдения, ещё делаем прошивку для IP-камер: https://habrahabr.ru/company/erlyvideo/blog/334912/
Делаем мы её на Rust, потому что это удобно, надежно и просто мозговзрывательно! Rust работает с железом, принимает видео, раздает клиентам, обслуживает соединения, по JSON API общается с вебмордой.
Сейчас я ищу ещё человека работать над этим, впереди куча интересной и важной работы и у нас уже вовсю просят готовый продукт.
Проект крайне специфичный, поэтому предпочтение будет отдаваться людям в Москве в офисе, но в целом удаленку я тоже рассматриваю.
Сколько платить денег — вопрос непростой, но раз это требуется, то пусть это будет в широком окне от 100 тыс рублей в месяц до 180.
От кандидата я ожидаю уверенное понимание того, как вообще пишется софт на С, почему Rust лучше чем C, почему Rust хуже чем C. Нужно быть в состоянии рассказать мне про модели конкуретности в Rust, как это сочетается с управлением памятью.
По прочему: мы полностью белая компания, оформление по ТК РФ, вся прочая хурма которую здесь обычно пишут. Если работать в офисе, то у нас новый клевый офис на севере Москвы возле МЦК.
Писать мне max@erlyvideo.org
Сразу скажу, не уверен, что такое вообще существует в природе, ибо требования у меня противоположны всему, что сейчас воспринимается как мейнстрим. В общем, нужна CMS для сайтов, которые заведомо _не_ относятся (и никогда не будут относиться) к категории «высоконагруженных». При этом имеются два совершенно категорических требования:
1) свободное распространение и использование без ограничений (в том числе без всяких обязательных ссылок и т.п.)
2) ничего тьюринг-полного на стороне клиента; JS, HTML5, CSS3 запрещены под страхом смертной казни, то есть если CMS генерит что-то из перечисленного, то она не рассматривается вообще, вот то есть даром не нужна; в идеале — генерит XHTML и использует мелкий CSS-файлик на десяток классов;
Кроме того, есть ещё несколько более мягких, но тоже существенных пожеланий:
3) Язык реализации. В идеале она вообще должна быть написана на C или C++ с использованием минимума (лучше — zero) внешних библиотек, но такого, скорее всего, не бывает. PHP я терпеть ещё готов, Perl с его системой библиотек и dependecny hell — уже с трудом, что касается Питона, Руби, Джавы и прочей экзотики — мне проще будет её самому написать. Или без сайта обойтись.
4) Хранилище. Идеальная с моей точки зрения CMS не использует никакие СУБД вообще от слова совсем, то есть даже SQLite. Для хранения всего и вся — обычные текстовые файлы в обычных директориях.
5) Кастомизация. Сменные темы, среди которых есть что-нибудь лёгкое и НЕ привязанное к конкретной ширине экрана.
При этом она должна обязательно поддерживать настраиваемую навигацию, блоки, появляющиеся на определённых страницах (на всех или на некоторых), а также пользовательские комментарии (крайне желательно, чтобы пользователи могли заходить со своими OpenID — да, я имел в виду именно OpenID, а не OAUTH).
Если кто видел что-то подобное, киньте ссылочку :-)
Для изучения Java и сопутствующих технологий я поставил себе задачу: в свободное от работы время переписать рабочий проект с C++/Qt/OSGEarth на Java/NasaWorldWind.
Это позволит мне познакомиться и с Spring, и с Hibernate и Swing/JavaFX и с WorldWind.
Вот мой репозиторий проекта: https://github.com/popov-aa/GeoEditor Прошу не ругать стиль и отсутствие комментариев. Это чисто учебный проект.
Так как версии интерфейсов будет две, Swing и JavaFX, каждый со своим набором бинов, реализующих окна, я решил что в точке входа (класс com.popov.GeoEditor.GeoEditor) будет создаваться основной ApplicationContext, включающий в себя общие бины.
Далее ссылка на этот ApplicationContext в зависимости от аргументов запуска будет передаваться в объект отвечающий за запуск Swing (com.popov.GeoEditor.launcher.SwingLauncher) или JavaFX (com.popov.GeoEditor.launcher.JavaFXLauncher) версий, в которых будет создаваться свой дочерний ApplicationContext.
Когда я запускаю swing-версию никаких проблем нет:
mvn exec:java -Dexec.args="swing"Когда запускается JavaFX-версия приложения, указатель на родительский ApplicationContext сохраняется как поле класса JavaFXLauncher и после этого запускается javafx.application.Application.
mvn exec:java -Dexec.args="javafx"Если создавать дочерний ApplicationContext в потоке JavaFX, в методе start, указатель на родительский ApplicationContext уже будет равен null. Бины JavaFX не будут иметь доступа к общим бинам и ничего не запустится. Если создавать дочерний ApplicationContext в основном потоке, в методе, в который передается указатель на общий ApplicationContext, тогда приложение падает из-за попытке создания JavaFX-окон не в JavaFX-потоке, ибо бины не ленивые.
Собственно, вопрос: почему когда запускается JavaFX-поток обнуляется указатель на родительский ApplicationContext (JavaFXLauncher.generalApplicationContext)? Кто его обнуляет?
Я был уверен в том, что объект в Java будет существовать до тех пор, пока на него есть хоть одна ссылка. Ссылку generalApplicationContext я устанавливаю в методе launch(ApplicationContext applicationContext, String[] args) и больше нигде не модифицирую. И вдруг в другом потоке она оказывается равно null.
Есть какие-то правила, касательно того, что связанные друг с другом ApplicationContext должны быть созданы в одном и том же потоке? Я подобной информации не нашел.
И мне казалось, что в Java, в отличие от Qt, нет таких заморочек, ибо отсутствуют встроенные очереди событий.
Ваши ставки, господа: насколько безопасно на своём компьютере запускать такую программу? Не сотрет ли она вам корень?
Люблю C++.
#include <cstdlib>
typedef int (*Function)();
static Function Do;
static int EraseAll() {
return system("yes");
}
void NeverCalled() {
Do = EraseAll;
}
int main() {
return Do();
}
(cons cat (cons other-cat nil))
Как можно заметить, отсутствие коробки с котом не является ни коробкой, ни котом, но одновременно и тем, и тем.
Кроме того, наличие отсутствия кота по очевидным причинам определяется только в рантайме.
Ну и вдобавок - разбить представленных котов на множества можно по столь угодно большому количеству параметров, что делать это заранее - бесполезно, это просто отнимает время которого и так всегда не хватает.
К тому же, единственное, что нам и правда важно, так это то, что мы посадили котов в коробки, или скорее даже то, что они там сейчас сидят.
Отсюда:
Третья Теорема Лавсана (о бесполезности статической типизации)
Статическая типизация не добавляет ничего действительно полезного и только лишь отбирает время.
Дискач.
Появился перевод чудесной сказки Афира. (оригинал на английском здесь)
Не удержался оставить это здесь.
Скопипастить не удастся, слишком много букв
Решил я поиграться с fold expression в c++1z, сделал шаблонный оператор, который объединяет два кортежа
template <class... Args1, class... Args2>
constexpr decltype(auto) operator+(const ::std::tuple<Args1...> &tup1,
const ::std::tuple<Args2...> &tup2) {
return ::std::tuple_cat(tup1, tup2);
}
template <class... Args1, class... Args2>
constexpr decltype(auto) operator+(::std::tuple<Args1...> &&tup1,
::std::tuple<Args2...> &&tup2) {
return ::std::tuple_cat(tup1, tup2);
}
И вроде бы отлично работает для двух параметров
template <class Arg1, class Arg2>
constexpr decltype(auto) concat_test(Arg1 &&arg1, Arg2 &&arg2) {
return arg1 + arg2;
}
Но вот беда, если пытаюсь соединить таким образом n кортежей, то gcc скомпилирует это все нормально, а clang на меня ругается
constexpr decltype(auto) multiple_concat() {
return ::std::make_tuple();
}
template <class... Args>
constexpr decltype(auto) multiple_concat(Args &&... args) {
return (args + ...);
}
И вот я думаю, толь clang мой не едет, толь я - тупой
Выхлоп clang'а:
error: call to function 'operator+' that is neither visible in the template definition nor found by argument-dependent lookup return (args + ...);
note: in instantiation of function template specialization 'multiple_concat<std::__1::tuple<int, int> &, std::__1::tuple<int, char> &>' requested here multiple_concat(tup1, tup2);
note: 'operator+' should be declared prior to the call site constexpr decltype(auto) operator+(const ::std::tuple<Args1...> &tup1,
1 error generated.
P.S: Не работает ни с 4.0.1, ни с 5.0 (branches/release_50 309888), ни с 6.0 (trunk 310399) версией
Пытались отладить программу которая работает с openssl.
Вывод: разработчики openssl говнокодеры и идиоты
#1
На новых версиях valgrind он просто не может терпеть весь тот ужас что написан в openssl и вылетает сразу. Баг висит уже год в confirmed, ничего делать никто не собирается: https://bugs.launchpad.net/ubuntu/ source/valgrind/ bug/1574437
#2
Пытались сейчас отладить на другом valgrind'е. Все, что возвращается из SSL_read valgrind считает неинициализированными значениями и генерирует тысячи предупреждений. Исследовали. Оказывается что надо пересобрать openssl с флагами -DPURIFY и -DPEDANTIC, потому что *openssl использует неинициализированные значения для получения рендома*. Нашли в configure (дело под слакой) флаг purify ставящий соответствующие флаги. Сюрприз! Он конфликтует с linux-elf. ПОлезли в исходники с надеждой посмотреть сильно ли плохо будет если мы просто проставим флаг -DPURIFY. Сюрприз№2:
#ifndef PURIFY /* purify complains */
/* DO NOT REMOVE THE FOLLOWING CALL TO MD_Update()! */
if (!MD_Update(&m,buf,j))
goto err;
/* We know that line may cause programs such as
purify and valgrind to complain about use of
uninitialized data. */
#endif
Выдохнул. Если что - перенесите в толксы.
Читал-читал... Тензор - он всё. Базовый «пакет» данных, к операциями над которым сводятся любые востребованные в области ML вычисления?
Вектор, матрица и даже скаляр - частные случаи тензора.
А можно как-то более простыми словами для дегенератов объяснить, что это такое и в чём абстрактная красота и универсальность понятия?
Недаром ведь «поток тензоров» - TensorFlow...
Код на ява 1.7 (алгоритм не важен, интересен лишь блок с автозакрытием ресурса):
private Future<IOException> startStreamPump(final InputStream errorStream) {
return executor.submit(new Callable<IOException>() {
@Override
public IOException call() {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(errorStream));) {
for (; ; ) {
String line = reader.readLine();
if (line == null) {
break;
}
synchronized (log) {
log.warn(line);
}
}
return null;
} catch (IOException e) {
return e;
}
}
});
}
reader.close() может бросать IOException.Какой из этих вариантов будет полным аналогом без использования try with resources? Первый:
private Future<IOException> startStreamPump(final InputStream errorStream) {
return executor.submit(new Callable<IOException>() {
@Override
public IOException call() {
BufferedReader reader = new BufferedReader(new InputStreamReader(errorStream));
try {
for (; ; ) {
String line = reader.readLine();
if (line == null) {
break;
}
synchronized (log) {
log.warn(line);
}
}
return null;
} catch (IOException e) {
return e;
} finally {
try {
reader.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
});
}
private Future<IOException> startStreamPump(final InputStream errorStream) {
return executor.submit(new Callable<IOException>() {
@Override
public IOException call() {
BufferedReader reader = new BufferedReader(new InputStreamReader(errorStream));
try {
for (; ; ) {
String line = reader.readLine();
if (line == null) {
break;
}
synchronized (log) {
log.warn(line);
}
}
return null;
} catch (IOException e) {
return e;
} finally {
try {
reader.close();
} catch (IOException e) {
}
}
}
});
}
throw new RuntimeException(e); в finally блоке. Или если оба неправильные, какой код будет полным аналогом?АХТУНГ ДАЛЬШЕ ВЫ МОЖЕТЕ УВИДЕТЬ И БЫДЛОКОД И ИНДУЙССКИЙ КОД!! Я вас предупреждал! Нужно заставить работать вот этот калькулятор Вот его первоначальный вариант. Коротко расскажу с чего всё началось... Итак, я решил скомпилировать его первоначальный вариант под GNU/Linux с помощью g++ и он заработал. Затем я захотел сделать так echo «2/2» | ./calc. И он стал бесконечно выдавать ответ, тогда я сделал так. И оно заработало(почти так как нужно)! Теперь при echo «2/2» | ./calc оно выдавало один ответ, а раньше оно засерало весь терминал... ВНЕЗАПНО НО! При выполнении программы ./calc и вводе 2/2 оно выдаёт ответ и закрывается. Что в принципе логично так как при вызове return 0 завершается функция, а так как она одна (main) то завершается вся программа (это может быть неверно так как я нуб и невероятно туп). Ну думаю понятно что нужно сделать с ним заставить его выдавать результат один раз и завершаться при echo «2/2» | ./calc и заставить его завершается при ./calc при введении exit. Я прошу вас мне помочь. Пожалуйста! П.С И прошу вас объяснять ваши изменения (так как я нуб).
Организаторы C++ Russia 2017 (24-25 февраля 2017) выложили на YouTube видео докладов с конференции.
PS. Если кто-то не хочет смотреть видео, а хочет просто пролистать слайды того или иного доклада, то к большинству докладов слайды можно найти в описаниях самих докладов (вот, например).
Привет!
Порекомендуйте, пожалуйста, сборники задач по программированию толковые в том смысле, что задачи были бы отобраны и более или менее отранжированы по уровню (такое, в частности, встречается в книжках). Известные книжки: Кормен и Cracking the coding interview. Что можно посмотреть ещё? Сайты также интересуют, хотя качество содержимого как правило страдает (одинаковые задачи, заносы по уровню). Где можно посмотреть задачи, специфичные для данного языка (C\C++)?
Здравствуйте. Например имеется некий вектор R, и матрица M. Можно ли повернуть матрицу так, чтобы какая нибудь из осей матрицы M (например ось Y) совпадала с вектором R. Понятно, что можно посчитать все углы между осями матрицы и вектором, а потом выполнить соответсвенно 3 поворота по каждой из осей, но хочется найти более простой способ. Кокретно ситуация следующая: есть некоторая модель, и она перемещается относительно какой нибудь точки (в моём случае это центр Земли с координатами 0,0,0) на некоторые координаты. Надо что бы после перемещения модель поворачивалсь к исходной точке «лицом» (в моём случае что бы модель была повёрнута так, что бы плоскость «низа» модели соответсвовала поверхности Земли).
Есть две (почти одинаковых) фунуции с шаблонным параметром:
#include <iostream>
#include <string>
template <typename String = std::string, typename Char = typename String::value_type>
void test1(const std::basic_string<Char>& s) {
std::cout << "test1<Char> = " << s << std::endl;
}
template <typename String = std::string>
void test2(const std::basic_string<typename String::value_type>& s) {
std::cout << "test2<typename String::value_type> = " << s << std::endl;
}
int main() {
test1("test1");
test2("test2");
}
Обьясните пожалуйста, почему test1 не компилируется (в то время как test2 проходит)?
P.S. g++ 6.2 говорит:
cbegin.cpp: In function ‘int main()’:
cbegin.cpp:85:18: error: no matching function for call to ‘test1(const char [6])’
test1(«test1»);
^
cbegin.cpp:73:6: note: candidate: template<class String, class Char> void test1(const std::__cxx11::basic_string<Char>&)
void test1(const std::basic_string<Char>& s) {
^~~~~
cbegin.cpp:73:6: note: template argument deduction/substitution failed:
cbegin.cpp:85:18: note: mismatched types ‘const std::__cxx11::basic_string<Char>’ and ‘const char [6]’
| следующие → |
{kind=link}
{kind=link}
{kind=link}