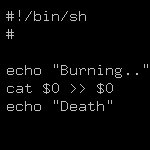
Написал, я к примеру, такое:
@larr = qw /a b c d e f/;
@rarr = qw /a b c d/;
@bigger = @larr;
@smaller = @rarr;
if (@rarr > @larr) {
@bigger = @rarr;
@smaller = @larr;
}
for (my $i = 0; $i < @bigger; $i++) {
print "bigger: $bigger[$i], ";
if (defined $smaller[$i]) {
print "smaller: $smaller[$i]\n";
} else {
print "smaller: 'null'\n";
}
}