Сабж: https://www.phoronix.com/news/LLVM-Ends-AMD-3DNow
Не знал, где написать, тут или Talks. Решил тут.
Так что если у кого остались Athlon до Athlon XP, то тогда использовать используйте gcc или clang 18.
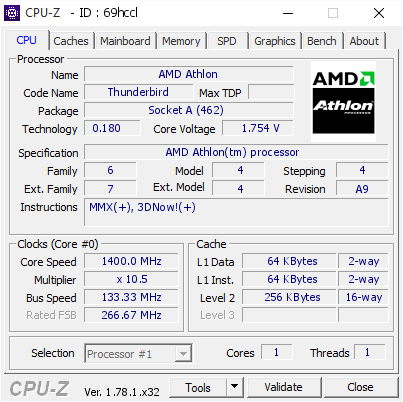
Скрин максимального процессора Athlon без SSE: http://valid.x86.fr/cache/screenshot/69hccl.png
Если кто-то никогда не видел как выглядит 3dnow,и кому интересно, вот пример функции вычисления векторного произведения.
https://gcc.godbolt.org/z/91vf1Whrx
struct Vector3 {
float x;
float y;
float z;
};
// Наивная версия векторного произведения
Vector3 naiveCrossProduct(const Vector3& a, const Vector3& b) {
Vector3 result;
result.x = a.y * b.z - a.z * b.y;
result.y = a.z * b.x - a.x * b.z;
result.z = a.x * b.y - a.y * b.x;
return result;
}
и 3dnow
Vector3 threeDNowCrossProduct(const Vector3& a, const Vector3& b) {
Vector3 result;
__m64 va = _m_from_int(*(int*)&a.x); // a.x | 0
__m64 vb = _m_from_int(*(int*)&a.y); // a.y | 0
__m64 vc = _m_from_int(*(int*)&b.y); // b.y | 0
__m64 vd = _m_from_int(*(int*)&b.x); // b.x | 0
__m64 temp1 = _m_pfmul(va, vc); // a.x*b.y | 0
__m64 temp2 = _m_pfmul(vb, vd); // a.y*b.x | 0
__m64 result2 = _m_pfsub(temp1, temp2); // a.x*b.y-a.y*b.x | 0
memcpy(&result.z, &result2, sizeof(float));
temp1 = _m_from_int(*(int*)&a.z); // a.z | 0
temp2 = _m_from_int(*(int*)&b.z); // b.z | 0
result2 = va; // a.x | 0
va = _m_punpckldq(vb, temp1); // a.y | a.z
vb = _m_punpckldq(temp1, result2); // a.z | a.x
temp1 = vc; // b.y | 0
vc = _m_punpckldq(temp2, vd); // b.z | b.x
vd = _m_punpckldq(temp1, temp2); // b.y | b.z
temp1 = _m_pfmul(va, vc); // a.y*b.z | a.z*b.x
temp2 = _m_pfmul(vb, vd); // a.z*b.y | a.x*b.z
__m64 result1 = _m_pfsub(temp1, temp2); // a.y*b.z-a.z*b.y | a.z*b.x-a.x*b.z
memcpy(&result.x, &result1, sizeof(result1));
_m_femms(); // Завершение работы с MMX/3dnow
return result;
}










{kind=link}