Недавний скриншот ![]()
Bagrov про OmegaT показал, что среди лорчан есть интерес к софту для переводчиков, а потому неплохо бы мне самому немного выйти из тени и рассказать, на что я трачу все свои свободные силы и время в последние пять лет - вдруг кому будет интересно, полезно и удобно:)
Для начала наверное немного предыстории - по основному образованию я лингвист-переводчик китайского и англиского языков, но как-то так вышло, что где-то на втором курсе я вдруг понял, что большая часть профессиональной работы письменного переводчика составляют не всякие классные художественные тексты, а бесконечная юридическая и техническая макулатура, едва отличимая одна от другой. Поэтому, продолжая про запас доучиваться на основной специальности, начал качаться параллельно в айти - линуксы, админство, немного разработки. Чем, собственно, в последние девять лет и кормлю себя.
И вот пока я ещё доучивался на переводчика, меня невероятно поражала неэффективность того, как мне и моим коллегам приходилось работать над переводами. Каждый делал всё сам по себе, словари часто бумажные, даже не электронные, тексты в ворде, перевод прямыми заменами внутри оригинального текста. Всё это медленно, муторно, никаких бэкапов, никакого переиспользования уже сделанных переводов. Тогда уже существовал Trados (вообще, есть ощущение, что этот мамонт был вообще всегда), но даже тогда, в середине нулевых он выглядел невероятно монструозным и уродливым. А на фоне свежеобретённого увлечения юниксами, очень важным фактором была кроссплатформенность, которой Trados, очевидно, не обладал. И на вот этом вот прекрасном фоне оформилась идея накостылить собственный велосипед, которым хотелось бы в первую очередь пользоваться самому.
Основные идеи, лежащие в основе Tolma.ch такие:
- кроссплатформенность
- коллективная работа над переводом
- максимальная простота и доступность интерфейса
- (и с последующим бумом смартфонов) максимально полноценная работа с мобилок
Учитывая всё вышесказанное и то, что я, в общем-то, был один со своей задачей, самым доступным вариантом реализации задуманного был веб-сервис. Миллион разных клиентов под разные платформы тащить даже сейчас кажется непосильной задачей.
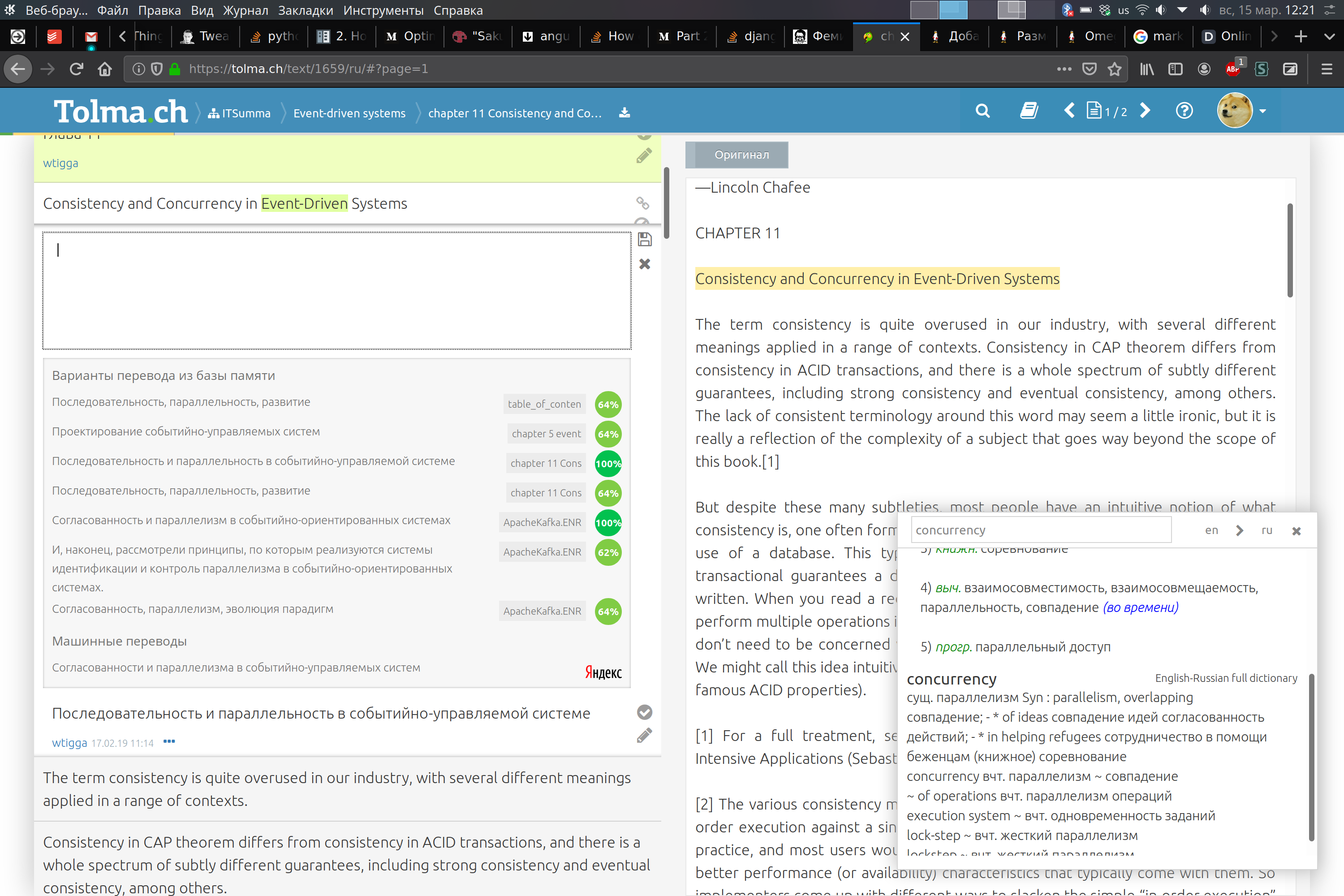
Результат почти пяти лет трудов можно наблюдать на скриншоте:) Что на нём вообще видно:
- документ бьётся на сегменты по предложениям
- в левом блоке список сегментов и, собственно, ведётся работа над переводом, в правом блоке - общий вид переводимого текста для контроля контекста. Можно переключаться между режимом оригинального текста и режимом отображения уже переведённых фрагментов
- сделанные переводы сохраняются в базы памяти и потом предлагаются, если достаточно похожи на текущий сегмент
- отдельно можно вести глоссарии (на скрине видно выделенный «Event-Driven»), чтобы соблюдать однородность терминологии. Прямо сейчас пока работают на простых регулярках, ищут точное соответствие, но на стейдже уже лежит версия со стеммером для европейских языков, чтобы искалось с учётом словоформ
- машинные переводы. Пока только Яндекс, т.к. только они дают бесплатную апиху. Но на уже готовую архитектуру довольно просто в будущем будет добавить любой другой MT-движок
- переводы от других людей, участвующих в проекте
- словари. Сделаны всплывающий окном, отображаются не постоянно, потому что нафиг надо.
Из того, что не видно на скриншоте, но оно есть под капотом:
- история правок сегментов
- тёмная тема для настоящих красноглазов
- мобильная версия. Функционально полностью аналогична десктопной, но в силу ограниченного рабочего пространства, увы, не так удобна. Со временем планирую добавить управление жестами, что должно будет снять часть анальных болей
- учитывая упор на кроссплатформенность - не важно, где, как и с какого девайса вы заходите каждый из разов - при открытии документа, над которым вы работали раньше, вы будете сразу перемещены к тому сегменту, на котором остановились
- превьюхи сегментов и их переводов в социалках/чатах, чтобы можно было что-то обсудить не переходя внутрь сервиса
- система ролей для проектов - владелец, редактор, переводчик, наблюдатель. С соответствующими ограничениями на спектр возможных манипуляций с данными
- базовая болванка под организации - надмножество над проектами, в которое можно добавлять переводчиков с распределёнными ролями и они будут автоматом раскидываться во все внутренние проекты. Впоследствии будет так же организован шаринг баз памяти перевода и глоссариев
Ближайшие планы - подключить Languagetool для QA переводов, расширенный поиск, как в какой-нибудь IDE, чтобы можно было осуществлять сложный поиск по паттернам + поиск и замена, расширить набор поддерживаемых языков перевода, сделать редактор баз памяти перевода.
>>> Просмотр (3000x2000, 595 Kb)









