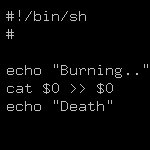
Привет!
Очень нужна помощь. Есть необходимость для обучения - отбирать логи за определенный день и записывать их в файл с датой (например, 2022-07-18.txt). Нет понимания - как отбирать все файлы за конкретный день и как автоматически создавать файл с логами.
Подскажите, какие у меня есть варианты и куда можно посмотреть для решения этой задачи?
Всех заранее благодарю!