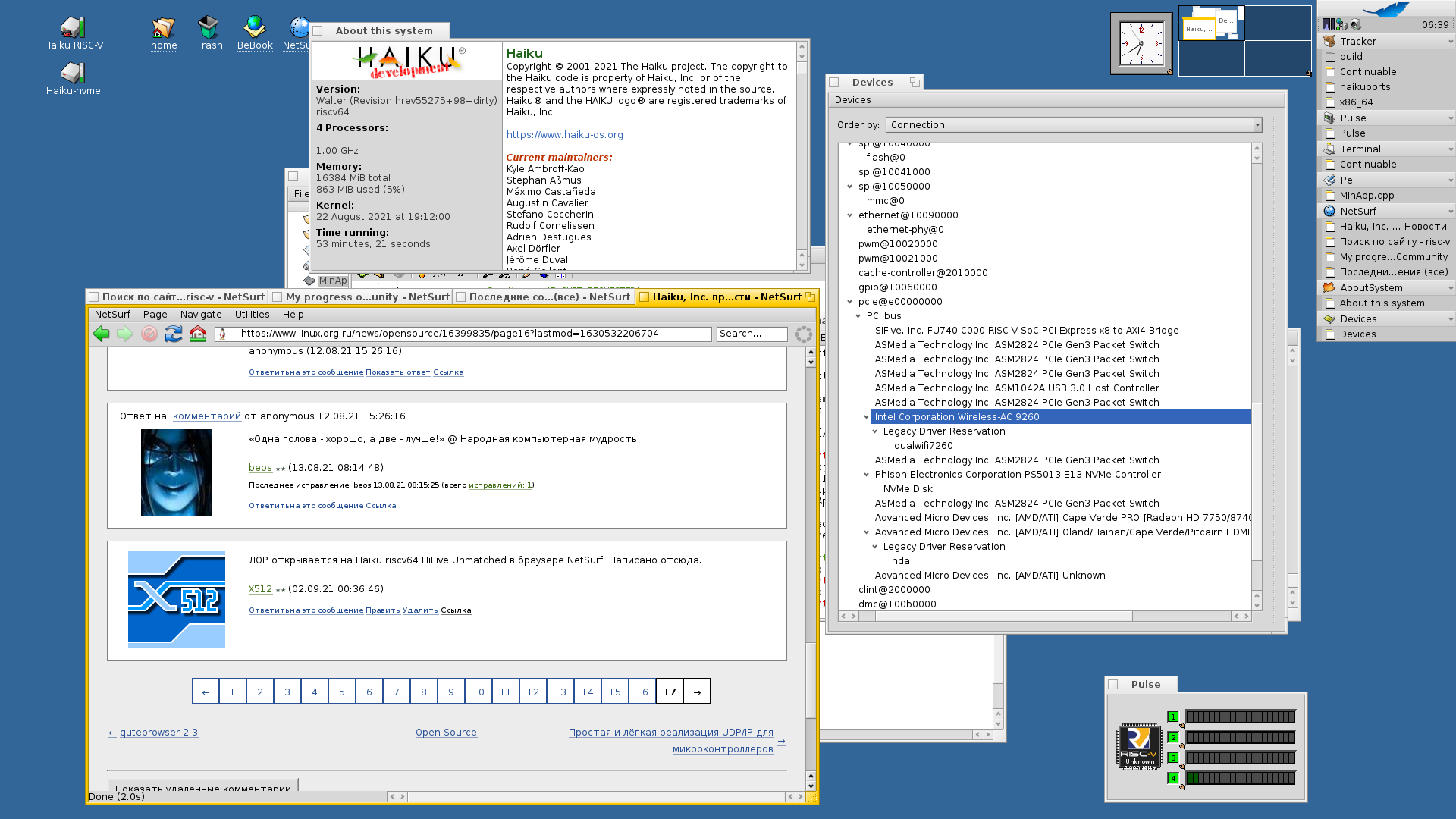
Сегодня открылся ЛОР в NetSurf в Haiku RISC-V.
С начала этого года делаю порт свободной UNIX-like операционной системы Haiku на процессорную архитектуру RISC-V (64 бит) (подробнее: My Haiku RISC-V port progress, My progress on real RISC-V hardware). Сейчас система уже неплохо работает на реальном RISC-V железе HiFive Unmatched, есть графика, сеть WiFi, поддержка многоядерности (SMP), пакеты портов собираются на самом железе, работает воспроизведение видео.
RISC-V — полностью открытая и свободная от каких либо отчислений процессорная архитектура, конкурирующая с ARM. Архитектура довольно новая и свободная от легаси вроде четырёх несовместимых наборов команд в ARM, разных MMU, и т.п.. Также архитектура очень простая и выразительная: я написал дизассеблер за два дня и минимально работающий порт Haiku за несколько недель. Для Haiku это первый рабочий порт на не x86-совместимую архитектуру. Остальные порты находятся в зачаточном состоянии без рабочего userland более 10 лет.
Компания SiFive производит открытые ядра RISC-V и готовые платы с полностью открытым программным обеспечением включая драйверы и прошивки. Я использую плату HiFive Unmatched. На плате есть шина PCIe так что можно использовать многие существующие драйвера Haiku без изменений.
Железо выглядит как-то так: раз, два.
Используемое железо:
- Мат. плата: HiFive Unmatched.
- Диск: Silicon Power SSD 256GB 3D TLC NAND M.2 2280 PCIe3.0×4 NVMe1.3 P34A60
- Сеть: Intel AC 9260 M.2 WiFi
- Видеокарта: AMD Radeon R7 250
>>> Просмотр (1920x1080, 263 Kb)




{kind=link}
{kind=link}