Ну какой конь придумал при обжимке разрывать зеленую пару?
Форум — Talks
Жутко мучительно же! А на приемной части все равно печатная плата, где пофиг...
Жутко мучительно же! А на приемной части все равно печатная плата, где пофиг...
Нашел вот это и это, там пишут, что нужно выбрать «LPD/LPR Host or Printer», внести IP, имя очереди (PCL_P1 — в свойствах принтера через веб-морду можно посмотреть), а в качестве ppd взять «PCL6/PCL XL Printer Foomatic pxlcolor».
Делаю так. Вот что в настройках получаю:
Driver: Generic PCL 6/PCL XL Printer Foomatic/pxlcolor (recommended) (color, 2-sided printing)
Connection: lpd://192.168.99.130/PCL_P1
Получаю «filter failed» при попытке печати. Пробовал другие варианты (и pxlcolor на pxlmono менял, и подключался по ipp, http, socket) — та же фигня (либо ошибка фильтра, либо просто тишина).
Между тем, если просто в браузере набрать http://192.168.99.130:9100/PCL_P1, то принтер печатает содержимое GET-запроса.
Как эту заразу настроить?
Нужно будет сервер БД приобрести, ориентировочно — от 50 до 100 тысяч рублей. Но лучше подешевле, чтобы на другие детальки еще хватило.
Вопрос: какую взять материнку? Да и вообще, какое нонче железо самое современное? А то я что-то уже лет 5 как тенденции железостроения не отслеживаю.
От материнки требуется: поддерживать в районе 32ГБ ОЗУ (самых распоследних DDR); не иметь интеловского чипсета (чтобы не было 12309); поддерживать приличный процессор (что там у интел нонче самое такое-растакое, но не слишком крутое?); аппаратный рейд тоже желателен; 4-6 портов SATA-2/SAS; главное: чтобы там не было костылей вроде UEFI или secure boot. Т.е. нужна нормальная материнка с нормальным биосом.
Народ, а как вы управляете шаговыми двигателями (через драйверы, у которых на вход надо подавать EN, CLK и DIR) с "малинки"?
Надо бы подключить 4-5 движков, а у этой шняги только один выход ШИМ.
И как одновременно управлять больше, чем одним шаговиком?
Вообще не представляю себе реализации. На микроконтроллерах все элементарно делается, а здесь-то даже прерываний по таймерам нет! Я уж не говорю про генерирование N импульсов ШИМ...
P.S. Вариант с потоками и usleep/select/poll/epoll сразу отметаю: бред.
Что-то не получается у меня запустить loopback-test отсюда. Получаю ругань:
can't set spi mode: Inappropriate ioctl for device
Aborted
Ядро 3.12.25+
интересно, что везде пишут о двух устройствах, а у меня в /dev/ только одно:
ls /dev/spi*
/dev/spidev0.0
Что я мог промухать?
// кстати, есть еще более свежий тест, но там нужен какой-то заголовочный файл с SPI_TX_QUAD и прочим. Где его взять? Или это нужно более свежее ведро ставить?
Поделитесь, пожалуйста. А то ну сил моих нет освоить ебилдописание.
Что-то вот решил я скомпилять свою прошивочку на домашнем компьютере. И охренел: у меня нет компилятора.
КАК? Я не могу нагуглить, как его (arm-none-eabi) поставить в генте! Почему-то в школоарчике он ставился элементарно. А во вроде бы серьезном дистре — хрен вам!
Как это?
Я в шоке!
И еще вопрос: как культешные приложения поставить без фонона? Они уже задолбали "блымцкать"! Какой чудак на букву "м" добавил звуки в оконные приложения?
Итак, задача: с N видеокамер покадрово снимается при помощи ffmpeg видеопоток и обрабатывается. В циклическом буфере в разделяемой памяти эти картинки постоянно висят (а также туда складывается дополнительная информация + индекс последнего сохраненного изображения). Нужно клиенту (firefox) вывести в веб-странице это видео со скоростью, которую позволяет канал.
Как это делалось раньше: CGI посылал jpeg'и с разделителем, которые отображались в <img>, обновляемом по таймеру. Это было не очень хорошо + требовало постоянно перезагружать веб-страничку (т.к. браузеры до сих пор текут!).
Хочется: отображать видео, которое не будет приводить к утечке памяти в браузере. Но не представляю, как это реализовать.
Клиент постоянно соединен с сервером через вебсокет (по нему идут асинхронные команды и ответы сервера), т.е. можно писать в вебсокет команду «дай мне следующий кадр» и забирать его как-нибудь.
Но как по-человечески отображать, чтобы не текла память браузера? Если опять передавать jpeg'и (пусть через вебсокет) и в канве их рисовать, то память будет течь (т.к. до сих пор в браузерах не реализовали сборщик мусора).
На ум приходит псевдо-html5-streaming. Но не приходит, как сделать.
Подкиньте идей, пожалуйста.
Помнится, Евгений (cast  Evgueni) советовал мне выложить куда-нибудь на гитхабе книжки/методички. Но вот что-то сомневаюсь я: гитхаб же для кода предназначен.
Evgueni) советовал мне выложить куда-нибудь на гитхабе книжки/методички. Но вот что-то сомневаюсь я: гитхаб же для кода предназначен.
А нет ли каких ресурсов, куда литературу выкладывают в исходниках? Чтобы человечество, так сказать, могло пользоваться результатом трудов твоих?
Думаю, кому-нибудь может пригодиться. А то болтается на полудохлом сайте на «народе», да еще и без исходников кое-что...
Обычно для аутентификации на веб-сервисе я пользовался следующим алгоритмом: после нажатия на кнопочку login пользователь перебрасывался на https-страничку ввода логина-пароля, сервер сверял хэш пароля с хэшем из БД для соответствующего логина и если все ОК, отсылал пользователю куку и возвращал его на нешифрованную страничку.
Но с https постоянная проблема: надо генерировать свои сертификаты и объяснить пользователю, что при запросе браузера на подтверждение, нужно жамкнуть «да».
Тут я придумал такое решение, работающее безо всяких SSL: пользователь вводит логин-пароль, получает от сервера некий случайный ключ, прислюнивает в качестве соли хэш своего пароля и полученный хэш отправляет обратно серверу. У того уже есть хэш пароля, и он выполняет такую же операцию. Если результат одинаковый, пользователю высылается ключ, который сохраняется не в куках, а в localStorage (по-моему, это удобней). При последующих соединениях пользователь лишь указывает этот ключ. А сам ключ имеет определенное время жизни. При желании его можно тем же самым методом обновлять, не требуя у пользователя перелогина (если, конечно, он не закроет страничку и не выждет времени отзыва ключа).
Как вам такая идея? Взлетит? Больше всего меня беспокоит устойчивость метода к атаке man-in-the-middle.
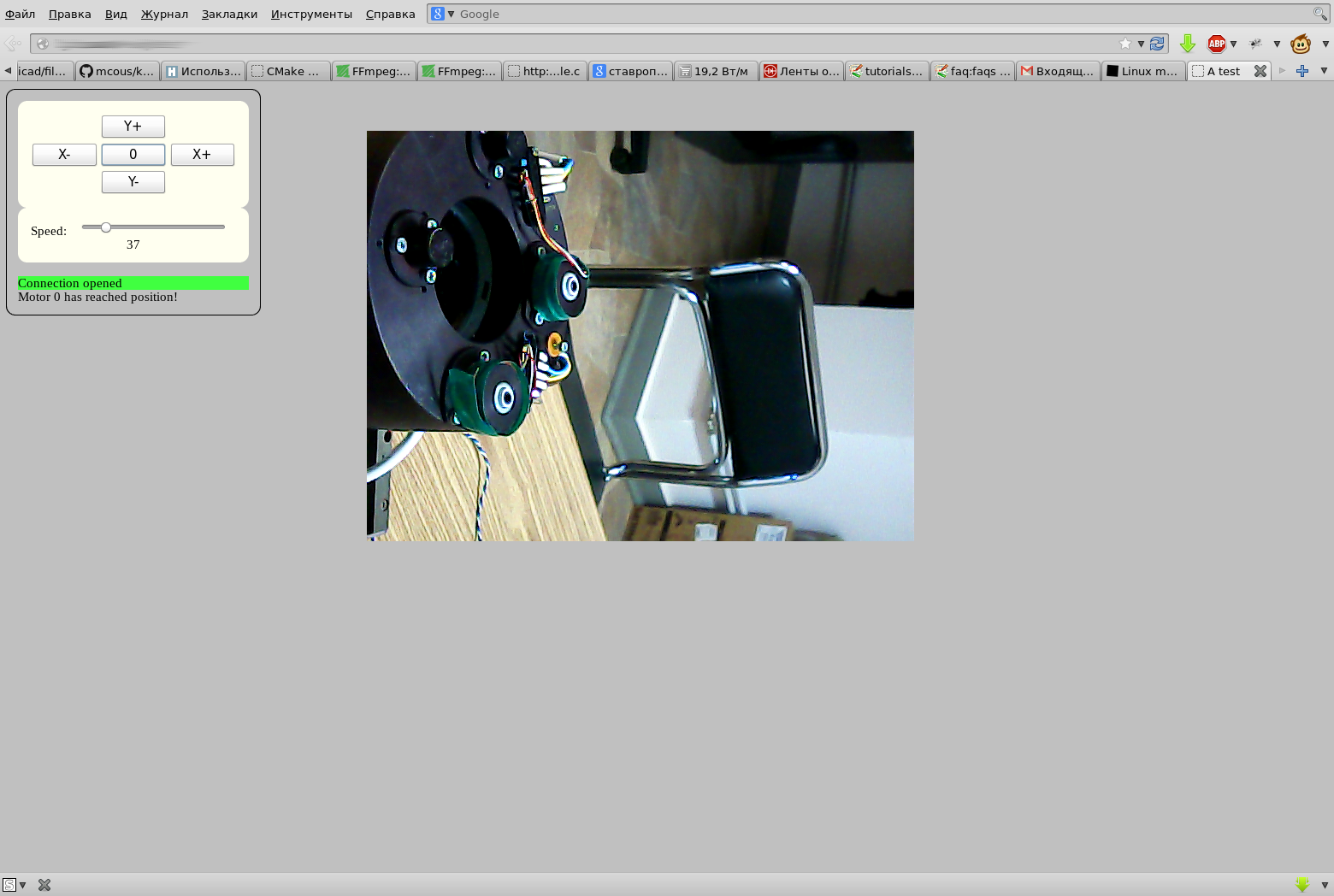
Наконец-то я частично воплотил идею еще трехлетней давности — использовать вебсокеты для управления приборами.
Вот такая простая веб-морда позволяет двигать два шаговика. Видео на экране — это запущенный по ssh mplayer (железяка расположена неблизко, поэтому для визуального контроля что куда движется, поставили вебку), пока видео я не встроил в веб-морду. Но ffmpeg для этих целей тоже начал помаленьку осваивать. Как раз вебсокеты помогут регулировать скорость потока в зависимости от «толщины» канала.
Жаль, что маловато в интернете примеров работы с вебсокетами, а документация скудная.
Вот захочу я, допустим, реализовать функцию malloc на микроконтроллере (раньше, правда, никогда такой необходимости не нужно было, но если брать МК аж с 512К флеша и 64К ОЗУ?) И как мне узнать, сколько из этих 64К я могу честно откусить на что-нибудь вроде
mempage _pages[SIZE];
SIZE?Понятно, что по memmap из даташита можно определить размер области данных, но как определить, сколько из этого объема займут всякие вспомогательные данные — глобальные переменные, адреса переходов и т.п.?
Извиняюсь за глупый вопрос, но интересно.
Смотрю — уже 96, а было 100. В уведомлениях пусто. И как такое возможно?
Хочу сделать по-человечески установку кикадовских библиотек, сконвертированных из игла. Нужно всего-то скачать архив и распаковать его в нужную директорию.
И таки что бы вы думали? Сплошные матюки! Вот чего сделал:
DESCRIPTION="Kicad components converted from Eagle"
HOMEPAGE="http://library.oshec.org/"
SRC_URI="http://library.oshec.org/all.tar.bz2"
LICENSE="GPL-2"
SLOT="0"
KEYWORDS="arm mips sparc x86 x86_64"
ADIR="${D}/usr/share/kicad/library/eagle"
src_install() {
dodir ${ADIR}
cp -R "${WORKDIR}/converted/" "${ADIR}" || die "Install failed!"
}
Я замучился уже: dodir ${ADIR} матюкается, что не может создать директорию; если не делать ее, то тупо распаковывается и устанавливается в /work/...
Ну вот что за нафиг? Мануал на ебилдописание такой, что руки оторвать хочется составителю! Лучше бы примеров понаделали побольше, чем расписывать 100500 ненужно.
Перемещено stave из talks
Для отладочной работы с железякой я сварганил простейший велосипед. Никаких потоков: просто поочередный опрос (select) терминала и cdc-acm с чтением, если есть данные. На малых размерах посылки это работает, а вот на больших почему-то нет-нет, да происходит косяк: считываются данные из первого буфера (64 символа — размер буфера USB cdc-acm), а второй пропускается. И получается обрезанный вывод данных.
Я уже время задержки опроса терминала до 500мкс уменьшил (чтобы было явно меньше времени между опросами USB), но все равно получаются пропуски.
Неужто никак не обойтись без потоков (т.е. слушать USB одним потоком, запихивая данные куда-нибудь в очередь)?
Гмыло матюкается, что уже с 16 сентября не в состоянии с тындекса мыло забрать. Там что, поломали что-то?
// пароли не менял.
Очень хочу подтянуть свои знания по цифровой обработке изображений. А может быть даже попытаться изучить opencv (говорят, она уже не тормозит), чтобы покончить с велосипедостроением.
Ищу «gonzalez woods digital image processing», как минимум 2012 года выпуска (нафиг старье? тем паче, книгу ~2004-го я уже читал). Нахожу оригинал по бешеным ценам от 2000 рублей (+ доставка примерно столько же). В переводе тоже не меньше 1500 рублей. Это что за прикол?
Та же песня с более-менее свежими книжками по opencv.
Я хренею, дорогие товарищи!!! Эдак вообще обыдлеем скоро, если на книжку нужно будет треть зарплаты тратить!
Вот такое странное сообщение выдает мне ffmpeg после попытки "подчистить хвосты".
[tl;dr]
Я начал пилить новую версию "астровидеогида" (сбор и обработка в реальном времени видео с видеокамеры подсмотра, выдача команд исполнительным приводам для коррекции поля — чтобы объект никуда не "убегал" при мелких колебаниях телескопа, а также коррекция телескопом при ошибках сопровождения), т.к. мне надоело для каждой новой камеры/платы видеозахвата допиливать модуль. Я решил использовать ffmpeg: пусть он жирный, зато проблем сразу меньше. Один демон будет просто хапать видео и в shm складывать в циклический буфер 4 последних кадра (раньше так и работало), а еще в shm будет складывать вычисленные координаты смещения опорного объекта (раньше сразу отправлялись команды на исполнительные приводы). Это позволит разделить демон захвата и исполнительный демон → проще будет разрабатывать новые устройства.
[/tl;dr]
Вот ссылка на мои начинания. Кода пока немножко. Проблема в файле capture.c: функция free_videodev() вызывает матюки:
[video4linux2,v4l2 @ 0x62e560] Some buffers are still owned by the caller on close.
Вопрос: мне наплевать на эти матюки, или же попытаться найти ту неведомую штуку, которая продолжает занимать память? Вроде бы, высвобождаются все ресурсы. В коде ffmpeg черт ногу сломит: очень уж много всего.
Читаю форумы, и везде советуют вместо явной установки CMAKE_INSTALL_PREFIX сначала проверить, а не ввел ли пользователь свой путь (что логично). Однако, у меня почему-то внутренняя переменная CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT принимает значение false, несмотря на то, что cmake туда запихнул неправильный путь /usr/local:
project(${PROJ})
if(CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT)
message("def")
endif()
# change wrong behaviour with install prefix
if(CMAKE_INSTALL_PREFIX_INITIALIZED_TO_DEFAULT AND CMAKE_INSTALL_PREFIX MATCHES "/usr/local")
message("Prefix!")
set(CMAKE_INSTALL_PREFIX "/usr")
endif()
message("Install dir prefix: ${CMAKE_INSTALL_PREFIX}")
Сообщения "def" нет, сообщения "Prefix!" нет. Путь — /usr/local
Как с этим бороться? Раньше я просто менял
set(CMAKE_INSTALL_PREFIX "/usr")
P.S. cmake 2.8.10.2-5
| ← назад | следующие → |