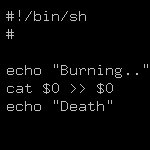
Всем привет
сильно не пиннайте, занимаюсь переносом впервые (и с линукс не очень, только установки чего-либо, по мануалам)
вводные:
есть система с умирающими дисками, нужно все перенести на новый сервер.
с livecd загружен
как скинуть lvm разделы (в lsblk их вижу) на новую машину (или промежуточную) и там (на новой) развернуть?