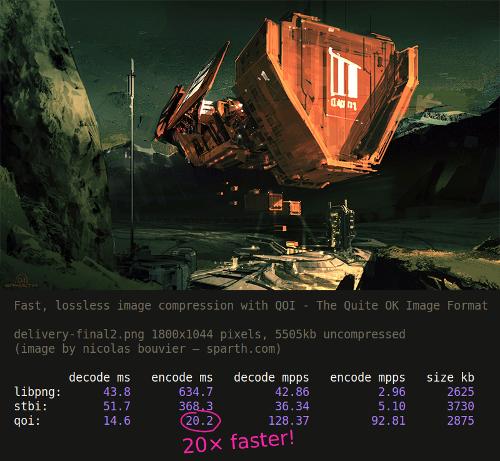
Доминик Саблевски представил новый и невероятно простой в реализации формат изображений QOI (Quite OK Image). По представленным тестам, при сжатии изображений QOI производительнее PNG в 20–30 раз, а при распаковке — в 3–4 раза.
Доминик признаётся, что не является экспертом в области сжатия изображений. Идея создать новый простой и эффективный формат изображений пришла к нему во времена работы с MPEG-1. Его целью была скорость и простота.
Файлы QOI больше по размеру, чем PNG на 10–50 % в зависимости от картинки, поэтому QOI стоит применять, когда необходима скорость.
Исходный код на C, состоящий из одного универсального файла, доступен на GitHub.
В данный момент формат проходит обсуждение финальной спецификации с заинтересованными пользователями.
Также доступны реализации на Zig, Rust, Go, TypeScript, Python, C#. Поддержка QOI добавлена в библиотеку SAIL.
Для пользователей Arch Linux в AUR доступен пакет qoi-git.
>>> Замеры скорости и размеров изображений
>>> Подробности








