erzent, тут тобой интересуются :)
Форум — Talks

erzent, тут PenguinSociophob ( anutik) спрашивает, где ты живёшь :) Она в Питере, очень хочет тебя увидеть ;)
erzent, тут PenguinSociophob ( anutik) спрашивает, где ты живёшь :) Она в Питере, очень хочет тебя увидеть ;)
Поглядел я тут на пацанов и увидел прогресс в их глазах. Поэтому я решил вести тут свой бложик, в котором я буду толкать матчасть, разбирать/разрушать всякие мифы и легенды, а так же их обсуждать с пацанами. Банить меня не надо - тут всё будет очень культурно.
Это будет формат для самых маленьких, где я буду показывать как что-то пилится по-пацаночке. Его задача - на примерах пересказать штеудмануал тем, кому лень его читать, но кто очень любит спорить про код, перфоманс и матчасть. Ну и просто интересные наблюдения.
Изначально я хотел написать про то: что такое бесплатные вычисления на примере is_range() + сумма елементов массива, но тут выявилась смешная особенность, поэтому пока без is_range().
Начнём с простого - сумма елементов(float) массива. Как написать её быстро? Обычный крестопоц сделает так:
auto summ = accumulate(begin(vec), end(vec), 0.)
Этот код выдаёт 5.6GB/s(мы всё бенчим в л1д 32килобайта массив). Казалось бы, если бы мы слушали всяких «гуру», которые нам говорят: accumulate() - оптимизирован, «ты что умнее создатели stl"а?», «конпелятор умнее тебе - сам всё делает оптимально», «руками что-то делать слишком сложно и не нужно» - то мы бы там и остались с этими 5.6ГБ, но мы пойдём дальше и поймём почему так, и является ли это тем, что намн ужно.
Но посмотрев на код - он не векторизован:
addq $4, %rdx
vcvtss2sd -4(%rdx), %xmm2, %xmm2
vaddsd %xmm2, %xmm1, %xmm1
Почему? Патамучто это основная флоатпроблема: Он не ассоциативен - флоат не имеет в себе точных представлений всех чисел входящих в диапазон его «представления» т.е. порядкопроблемы.
Поэтому конпелятор НЕ ВЕКТОРИЗУЕТ флоат по умолчанию, ну никак. Даже такую банальщину.
Для решения этих проблем - есть ключик -funsafe-math-optimizations, который входит в -ffast-math, который кладёт на точность при вычислениях. Добавив его мы получаем уже 44.9GB/s.
Но теперь мы получаем ещё одну проблему - надо думать: «как бэ сунуть эту ключик не повредив там, где этот ключик не нужен».
Поэтому ноцанам, которые хотят быстро и не хоятт рандомных жоп из-за тупости конпелятора - пишут всё руками. Допустим на той же сишке это пишется так:
double memadd_autovec(buf_t buf) { //5.609465GB/s, либо 44.969652GB/s с ffast-math
float * it = buf_begin(buf), * end = buf_end(buf), summ = 0.;
do {
summ += *it++;
} while(it != end);
return summ;
}
double hsumf(__v8sf v) {
return (v[0] + v[1] + v[2] + v[3] + v[4] + v[5] + v[6] + v[7]);
}
double memadd_vec(buf_t buf) { //45.652002GB/s и класть на ffast-math
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = {};
do {
summ += *it++;
} while(it != end);
return hsumf(summ);
}
Т.е. разницы никакой нет, кроме нужной нам реализации горизантального сложение вектора. Когда я говорил пацану: «векторную сишку для написания быстрого кода юзать намного проще, чем плюсы» - поцан нипонимэ, да и любые пацаны скажут - ну дак с -ffast-math оба выдают по 45гигов - нахрен эта сишка нужна?
А вот зачем:
double memadd(buf_t buf) { //132.878440GB/s
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = {};
do {
summ += *it++;summ += *it++;summ += *it++;summ += *it++;
} while(it != end);
return hsumf(summ);
}
Это называется пацанский анролл копипастой, а вот заставить конпелятор нормально что-то разанролить очень сложно.
Если бы мы слушали всяких «гуру», которые нам вещают: «анрол говно и не нужен» - мы бы так и седели с 45-ю гигами, а так мы сидим с 132.878440GB/s. Т.е. анролл нам дал немного не мало ~300%.
Но основная мысль, которую толкают всякие «гуру» - это не надо следить за тактами/считать такты и прочее. Но мы о5 сделаем наоборот и посмотрим что будет.
Т.к. наш юзкейс упирается на 99% в throughput и дёргается одна инструкция, то нам достаточно просто считать теоретическую производительность для моего камня. 4.5(частота камня)*8(т.е. у нас камень с avx, то там вектор 32байта, либо 8флоатов.)*1(throughput нашей инструкции - в данном случае vpaddps из интел мануала). Т.е. 36гигафлопс, либо ~144гига. Т.е. мы сняли овер 90% теоретической производительности - остальные 10% у нас ушли в наши циклы, всякие горизонтальные суммы вектора и прочее, ну и конечно же чтение данных из кеша.
Но самое смешное - на моём хасвеле умножение имеет throughput 0.5 - т.е. на хасвеле умножение быстрее сложения. Это новая забористая трава у интела.
Казалось бы - какой жопой сложнее оказалось медленнее умножения - а вот так, на всяких штеудах производительность уже давно зависит не от каких-то технических возможностей, а от маркетинга и хотелок.
Поэтому очень смешно слушать, когда какие-то пацаны говорят: «float point имеет такую же производительность как и инты» - нет, оно имеет такоу же производительность лишь по причине того, что на штеуде инты тормазят так же, как и float.
И чтобы окончательно в этом убедится - мы взглянем на fma(вариации умножения со сложением/вычитанем), которые имеют throughput 0.5 - да, да - на хасвеле умножение+сложение в 2раза быстрее просто сложения. Это уже не просто трава - это что-то принципиально новое.
У целочисленного сложения же throughput 0.5 и казалось бы, если мы поменяем в нашей функции float на int - у нас будет сложение работать в 2раза быстрее, но это не так. Оно выдаёт те же 130гигов, а почему?
Вообще у камня есть такая фича, допустим у нас:
add $1, %reg0//вот тут инструкция add залочит регистр reg0
add $1, %reg0//а эта инструкция уйдёт в лок до особождения предыдущей инструкцией регистра reg0
Чтобы такой жопы небыло - есть специальная фича:
add $1, %reg0//lock reg0
add $1, %reg0//И тут вместо того, чтобы уйти в лок - камень вместо reg0 даёт инструкции любой свободный регистр.
Эта фича называется прееименование регистров, либо как-то так - мне лень гуглить.
Дак вот штука в том, что фича работает через жопу. Мне лень читать мануал и искать почему так, но штука в том, что она ограничивает throughput. На умножении и целочисленном сложении она огранивает throughput c 0.5 до 1.
И вот я решил заюзать сложении через fma:
__v8sf fmaadd(__v8sf a, __v8sf b) {
return _mm256_fmadd_ps(_mm256_set1_ps(1.), a, b);// a + b * 1. == a + b.
}
double memadd_fma(buf_t buf) {
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = {};
do {
summ = fmaadd(summ, *it++);
} while(it != end);
return hsumf(summ);
}
Но меня ждала жопа: 27.347290GB/s, причем не анролл и ничего не помогал. Я уж подумал, что мануал наврал, но позже до меня допёрло: у неё latency 5тактов и ((4.5×8)÷5)×4 ~= 29гигов - т.е. я получаю производительность с её latency, но какой жопой оно так?
Потом я вспомнил, что гцц гинерит анрольный код вида:
add $1, %reg0
add $1, %reg0
//а не
add $1, %reg0
add $1, %reg1
Т.е. на неё вообще не работает переименовывание регистров - и инструкции постоянно в локе. Я это проверил и оказался прав. Ну и я написал такой мемадд:
__v8sf fmaadd(__v8sf a, __v8sf b) {
return _mm256_fmadd_ps(_mm256_set1_ps(1.), a, b);
}
inline void fma_10way_finality(__v8sf * cache, __v8sf * it, __v8sf * end) {
switch(end - it) {
case 8:
*(cache + 7) = fmaadd(*(cache + 7), *(it + 7));
*(cache + 6) = fmaadd(*(cache + 6), *(it + 6));
case 6:
*(cache + 5) = fmaadd(*(cache + 5), *(it + 5));
*(cache + 4) = fmaadd(*(cache + 4), *(it + 4));
case 4:
*(cache + 3) = fmaadd(*(cache + 3), *(it + 3));
*(cache + 2) = fmaadd(*(cache + 2), *(it + 2));
case 2:
*(cache + 1) = fmaadd(*(cache + 1), *(it + 1));
*(cache + 0) = fmaadd(*(cache + 0), *(it + 0));
case 0:
break;
default: error_at_line(-1, 0, __FILE__, __LINE__, "bad_aligned");
}
}
double memaddfma_10way(buf_t buf) {
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = (__v8sf){};
__v8sf * cache = (__v8sf[10]){{}};
uint64_t i = 0;
while((it += 10) <= end) {
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
i = 0;
}
fma_10way_finality(cache, (it - 10), end);
summ = (*(cache + 0) + *(cache + 1) + *(cache + 2) + *(cache + 3) +
*(cache + 4) + *(cache + 5) + *(cache + 6) + *(cache + 7) +
*(cache + 8) + *(cache + 9));
return hsumf(summ);
}
Пришлось хреначить финалити, ибо тут «анролл» на 10, а почему на 10 - для максимального throughput"а - надо, чтобы каждый каждый регистр юзался через 5тактов - т.е. 10регистров.
И вся эта порятнка нужна для борьбы с тупостью конпелятора.
Это уже: 214.167252GB/s(раельно там в районе 250 - просто мой бенч говно). 107 гигафлопс на ведро. Из теоретических 144, но тут уже влияние кеша. Причем 50+ из которых выкидываются и просто бесплатные.
Теперь вопрос к пацанам - что нам дадут эти гагфлопсы, когда у нас будет массив не 32килобайта, а 32мегабайта? Зачем нужно выживать максимум, когда скорость памяти отсилы 20-30гигабайт и нам хватит даже С++ кода с ffast-math?
Ну и призываются упомянутые мною пацаны: mv - этот тот експерт, что вещал про «руками переименовывать регистры не надо» и «анрол ваще ненужен», emulek вещал про ненужность счёта тактов, и не понимал что такое «беслпатно», AIv - не понимал в чем проблема плюсов, ck114 - так же не понимал в чем проблема плюсов.
Бенчи: https://gist.github.com/superhackkiller1997/606be26fa158ef75501d - вроде я там ничего не напутал.
P.S. - не выпиливайте пж, пусть пацаны «нужно» или «не нужно». Мне интеерсно. Ну и там рекомендации пацанов.
Иногда во время переключения вкладок случайно переношу вкладку в отдельное окно: зажал кнопку мыши, немного потянул — и готово. Возможно ли, желательно без плагинов, отключить такое поведение, или вообще полностью отключить многооконность, чтобы все страницы всегда были вкладками одного окна?
Подскажите хорошую RPG (Ролевая игра) ?
Перемещено leave из talks
Прекрасная стендап-трагедиякомедия Григория Курячего (ALT Linux) на тему «Кризис UNIX way и фундаментальное IT образование» с январской конференции Альта:
https://www.youtube.com/watch?v=MAKZh-86qQ8
Избранные цитаты:
Ещё в 2008 году я учил, как это круто, что у нас есть много потоков событий, и из них мы фильтруем только те, которые нас интересуют, потом их агрегируем и складываем в человекочитаемого вида журнал, который может прочитать любой системный администратор. Это очень круто, только так щас никто не делает. Даже наш syslog складывает всё и не делает вот этой агрегации и фильтрации. Он просто складывает от такого-то процесса туда, от такого-то — сюда, грепайте — и вам будет счастье. Понятное дело, что это ещё один шаг к тому, чтобы складывать вообще все события в бинарный журнал и искать по нему специальным инструментом.
Когда вы в последний раз писали программу, используя X-протокол — рисовали квадрат через Х-протокол? Лично я — в 99-м году. Всё, что мы здесь привыкли считать нерушимыми основами — уже не основы. Всё, мир обрушился, пойду переквалифицируюсь в переводчики.
Ещё один такой тренд — «не пишите на шелле — он медленный». Вот вы смеётесь, а это правда. Запустите полтораста тысяч шелл-скриптов — и они будут чудесным образом в полтораста тысяч раз медленнее работать.
Следующий пункт который разрушает наши представления о системе - профессионализация разработчиков. Задачи стали такие сложные, что выучив немного язык Си и воодушевившись знаниями о том, что существует Linux, невозможно принести пользу сообществу. Сообщество пользователей, соответственно, депроффесионализируется. Хороший пример — это пользователи Убунту.
Базовое понятие — пакет — подвергается наезду. Некоторые даже говорят: а давайте собирать вот такой бандл большой; зачем вам пакет? главное, чтобы бандл работал — с набором пользовательского софта сразу.
Напоминаю пафос всего этого дела: мне совершенно непонятно, что на текущий день должно составлять содержание фундаментального курса по вычислительным системам.
На мой взгляд местами изрядно хромает, по крайней мере если рассматривать её именно как пособие для начинающего, который хочет с первого раза получить исчерпывающие сведенья об установке максимально простым и эффективным путём. Если полное отсутсвие упоминаний о distcc ещё можно понять (хотя как минимум упомянуть однозначно стоило бы), то молчание о localmodconfig и localyesconfig в разделе о сборке ядра не получается объяснить никак, и в контексте хэндбука выглядит настоящей подставой.
Этот неловкий момент, когда смыл кучу времени в унитаз, узнал об этом и теперь готов съесть свою шляпу от злости. А сколько ещё людей впервые открывало handbook и точно так же тратило уйму времени на неэффективный способ установки...
Inb4 бомбануло, проваливай на винду, всем пофиг
Стоял Windows, ставил Ubuntu, потом опять Windows. Ubuntu вроде снеслась под корень. Прошло 4 месяца... Сегодня включаю компьютер, а там Ubuntu, я, помня пароль, вхожу с испугом. Захожу в диски и вижу один диск(так как он там один на компьютере), в нем есть папка Windows и какие-то кэш-папки линукса, как от этого избавиться и что вообще произошло? Спасибо...
Когда-то делал подобный тред, но с тех пор много чего вышло.
1) без школьников/ц в форме. Т.е. если по возрасту школьники, то действо за пределами стен. Годятся джинсы, свитеры, кимоно, футболки, кофты, юбки, платья.
2) без размахиваний катаной/мечом/чем они там еще любят помахать в 21-м веке
3) без человекоподобных роботов а-ля меха. Нечеловекоподобные или как во времени евы, наоборот, желательны.
4) без «хакиров». Если и взлом компьютернов, то реалистичный. Социнженерия, подбор паролей, sql-инъекции, 0-day уязвимости итд.
5) Никаких истеричных воплей и кривляний
Почти все, что рекомендовали мне в прошлых тредах - посмотрел.
UPD:
как же я мог забыть:
6) не гарем
7) не «он ее хочет, аж кровь из носу, но она все время увиливает и френдзонит»
Силами кафедры теоретической физики физического факультета Новосибирского государственного университета были записаны лекции по физике. Исходные видеофайлы выложены в открытый доступ под лицензией CC-BY-SA 4.0.
Значимые изменения после предыдущего сообщения: Добавлены все лекции спецкурса Избранные вопросы нелинейной и хаотической динамики (Жирова О.В), добавлены в первый раз лекции по Двухфотонной физике (Сербо В.Г.), семинары по Физике элементарных частиц (Сковпень Ю.И.), Физики атомного ядра (Дмитриев В.Ф.), а также «Экскурсия» в теорию струн (Померанский А.А.). Появился неофициальный YouTube канал кафедры.
( читать дальше... )
Возможно, на ЛОРе, а может быть и нет, кто-то когда-то выложил pdf-ку про функциональное программирование на чистом C. Она была на английском языке и первый пример там был про генератор случайных чисел. Больше ничего я не прочёл. Кто-нибудь ещё её знает? Гугл такие запросы плохо понимает.
Парни, очень интересует сабжевая тема. Сейчас я потихоньку дизассемблирую листинги из K&R, идёт весело и непринуждённо, но я чувствую, что уже упёрся в потолок и хочется большего.
Посоветуйте, пожалуйста, что делать дальше? Может книги какие-то есть интересные, таски, etc?
Недавно группа исследователей обратила внимание, что можно инициировать повреждение отдельных битов DRAM-памяти путём цикличного чтения данных из соседних ячеек памяти (простой цикл с чтением содержимого памяти и очисткой кэша). Проблема обусловлена особенностью работы памяти DRAM, которая формируется как двухмерный массив ячеек, каждая из которых состоит из конденсатора и транзистора.
Исследователи безопасности из группы Zero продемонстрировали реальность создания рабочих эксплоитов, использующих уязвимость RowHammer
>>> Подробности
Как говорили древние отцы-основатели редактирования текстов: « Damnosa quid non imminuit dies¹ ? »
Но мы им отвечаем: « Tempora mutantur et nos mutamur in illis² ! »
Делимся полезными и интересными кусками из своих конфигов, а также демонстрируем, кто на какой статусной строке в данный момент остановился и использует. Также это касается не общеизвестных плугинов или настройки/интеграции общеизвестных и общеиспользуемых. В общем синтастик или ЗадротДерево сюда не нужно, наверное, писать.
Я могу предложить (кое-что известное, но будет полезно новичкам, если такие есть):
А теперь по статусной строке. Почти два года сидел на airline, но вот недавно перешел на lightline, которая быстрее стартует и легче кастомизируется, а также не содержит кучу неиспользуемых (лично мной) возможностей. Попробовал еще ezbar, но японец пилит его под себя, хотя там есть кое-что интересное, насчет скорости:
lightline: 229.019 000.003:
ezbar: 250.312 000.002:
airline: 276.823 000.003:
Вот такая у меня статусная строка: картинка, настройка здесь и здесь. Середина прозрачная, выведен размер файла, имя файла справа, голубой квадратик с + это модифицированный, но не сохраненный файл.
Показывайте ваши ништяки.
--------
¹ - лат. что не изменит губительное время
² - лат. времена меняются и мы меняемся с ними
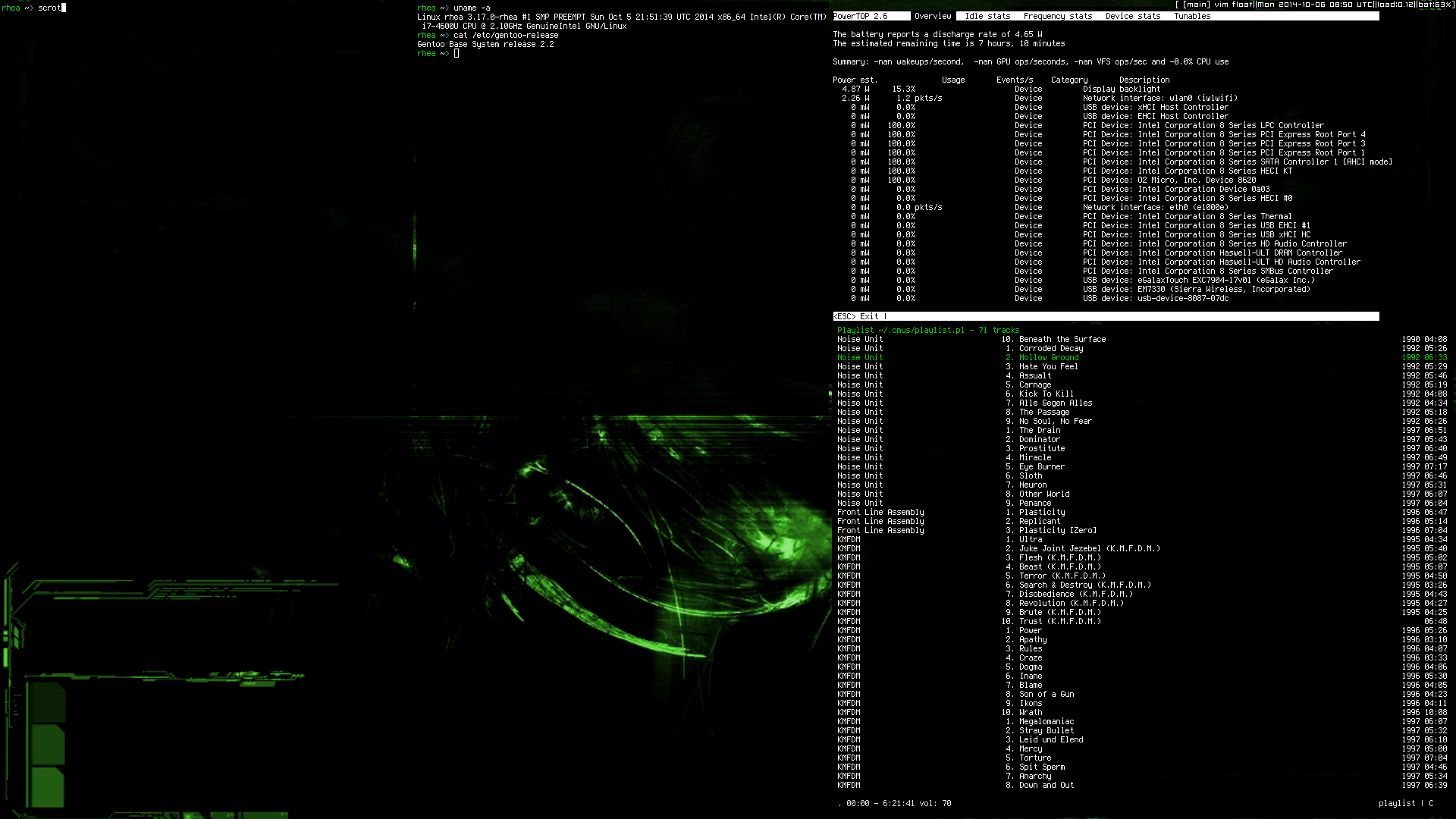
После ручного допиливания ядра и прочих радостей заставил ноутбук потреблять меньше 5W при работе с кодом и чтении комикс^Wдокументации. В итоге получается где-то 12-13 часов работы, что крайне полезно при периодических долгих перелётах в моём случае (розетки в самолётах я пока только в Emirates встречал).
На скриншоте показания powertop, cmus в качестве плеера и notion вместо wm. Ноутбук - Panasonic CF-AX3.
http://sharpc.livejournal.com/67583.html
У человека есть мнение, что должен знать каждый программист.
для Ъ:
Аппаратное обеспечение, Хоровиц-Хилл, полупроводниковая электроника/спинтроника/фотоника, транзистор, схемотехника, микрокод, технология создания процессоров, VID/PID, FPGA, Verilog/VHDL/SystemC, SISAL, Arduino, устройства памяти (ROM → EEPROM, RAM, SSD, HDD, DVD), RISC/CISC, Flynn's taxonomy ([SM]I[SM]D), принстонский и гарвардский подход, архитектуры процессоров, архитектуры x86
Процессоры, конвейеризация, hyper-threading, out-of-order execution, спекулятивное исполнение, branch predict, префетчинг, множественный ассоциативный кэш, кэш-линия/кэш-промах, такты, кольца защиты, память в мультипроцессорных системах (SMP/NUMA), тайминг памяти
Дискретная математика, K2, теорема Поста, схемы, конечные автоматы, клеточные автоматы, автомат Калашникова, ДКА и НДКА
Вычислимость, машина Тьюринга, нормальные алгоритмы Маркова, машина Поста, диофантовы уравнения Матиясевича, лямбда-функции Черча, частично рекурсивные функции Клини, комбинаторное программирование Шейнфинкеля, Brainfuck, эквивалентность тьюринговых трясин, проблема останова и самоприменимости, счетность множества вычислимых функций, RAM-машина, алгоритм Тарского, SAT/SMT-солверы, теория формальных систем
Языки программирования, грамматики, иерархия Хомского, теорема Майхилла-Нероуда, лемма о накачке и лемма Огдена, алгебра Клини, НДКА -> ДКА, алгоритмически неразрешимые задачи в формальных языках, Драгонбук, Фридл, регекспы и их сложность, PCRE/POSIX RE, БНФ, Boost.Spirit + Karma + Qi/Ragel, LL, LR/SLR/LALR/GLR, PEG/packrat, yacc/bison/flex/antlr, статический анализ кода, компиляция/декомпиляция/обфускация/деобфускация, Clang/LLVM/XMLVM, GCCXML, OpenC++, построение виртуальных машин, JiT/AoT/GC, DSL/DSEL
Алгоритмы и комбинаторная оптимизация, Кормен/Скиена/Седжвик/Кнут/Ахо-Хопкрофт-Ульман/Пападимитриу/Шрайвер-Голдберг/Препарата-Шеймос, структуры данных, алгоритмы, сложность и символы Ландау, классы сложности, NP-полные задачи, графы и деревья, потоки в сетях, матрица Кирхгофа, деревья поиска (особенно RB-дерево и B-дерево), occlusion detection, куча, хэш-таблицы и идеальный хэш, сети Петри, алгоритм русского крестьянина, метод Карацубы и матричное умножение Винограда-Штрассена, сортировки, жадные алгоритмы и матроиды, динамическое программирование, линейное программирование, diff-алгоритмы, рандомизированные алгоритмы и алгоритмы нечеткого поиска, псевдослучайные числа, нечеткая логика
всего 35 пунктов

Система: Ubuntu Server
ВМ: I3
Файловый менеджер: mc
Панель: I3bar
Терминал: Sacura 3.1.4
Тема Gtk3: Atolm
Тема Gtk2: Nodoka-Midnight
Иконки: Elementary
Давно приглядывался к тайловым ВМ, сама идеалогия показалась очень интересной. По ощущениям за 2 недели использования очень удобно, и гораздо быстрее чем с обычными окнами. Выбор на i3wm пал за простоту настройки из коробки.
В качестве локера использую штатный i3lock в небольшом скрипте пикселизации:
#!/bin/sh -e
# Take a screenshot
scrot /tmp/screen_locked.png
# Pixellate it 10x
mogrify -scale 10% -scale 1000% /tmp/screen_locked.png
# Lock screen displaying this image.
i3lock -i /tmp/screen_locked.pngВсем привет, недавно у меня стало возникать слишком много мыслей о том, насколько легитимно приводить типы указателей в некоторых случаях и не нарушает ли это правил strict aliasing.
Компилируется код такой командой (gcc 4.9.2):
gcc test.c -o /dev/null -O3 -Wall -Wextra
Случай №1. Есть какой-то буфер в виде массива чаров, полученный откуда-то (по сети, например). Хочется его распарсить, для этого привести char * к какому-нибудь struct payload * и работать со структурой; выравнивание и порядок байтов к вопросу отношения не имеют, считаем, что там всё правильно. Для примера можно для упрощения вместо struct payload взять обычный int — с ним происходит то же самое:
int main()
{
char buf[5] = "TEST";
int *p = (int *)&buf; // По стандарту char может алиасить любой тип, но не наоборот
*p = 0x48414559; // Но здесь предупреждения о нарушении strict aliasing почему-то нет
*(int *)buf = 0x48414559; // А вот здесь есть
// *(int *)(buf+1) = 0x48414559; // Вот так уже не будет, кстати
return 0;
}
test.c: In function 'main':
test.c:6:2: warning: dereferencing type-punned pointer will break strict-aliasing rules [-Wstrict-aliasing]
*(int *)buf = 0x48414559;
^
Вопрос: чем отличается доступ через указатель p и через buf, приведенный к int *? Почему в одном случае нет варнинга, в другом есть? Действительно ли в одном случае нарушается правило strict aliasing, а в другом нет? Или это потерянный варнинг? Или особенность реализации gcc?
Случай №2. Приведение struct sockaddr_in * к struct sockaddr *, использующееся повсеместно. Для чистоты эксперимента структуры объявнены вручную, а не взяты из хедеров. Да, их наполнение отличается от того, что там должно быть. Итак, я решил продолжить эксперимент с приведением типа указателя без промежуточной переменной.
#include <stdint.h>
struct sockaddr {
uint16_t sa_family;
char sa_data[14];
};
struct sockaddr_in
{
uint16_t sin_family;
uint16_t sin_port;
uint32_t sin_addr;
char sin_zero[8];
};
int main()
{
{
struct sockaddr_in addr;
((struct sockaddr *)&addr)->sa_family = 2; // Тут варнинга почему-то нет
}
{
char addr[16];
((struct sockaddr *)&addr)->sa_family = 2; // А тут есть, как и в предыдущем примере
}
{
uint32_t addr[4];
((struct sockaddr *)&addr)->sa_family = 2; // А здесь почему-то снова нет
}
return 0;
}
Господа, я в замешательстве. Вот моё мнение по этому поводу:
В первом примере нарушения правила strict aliasing есть в обоих случаях (char может алиасить любой тип, но не наоборот), однако варнинг есть почему-то в одном из случаев, в связи с этим вопрос: это недостающий варнинг или особенность поведения gcc?
Во втором примере нарушений правила strict aliasing нет, поскольку я обращаюсь только к объекту struct sockaddr. Однако в случае, когда addr — это массив чаров (как в первом примере), варнинг возникает. Здесь аналогичный вопрос: это лишний варнинг, или же смысл различен?
Ну и один глобальный вопрос: если я где-то в своих рассуждениях ошибаюсь (или чего-то не понимаю), то где?
3 дня назад вышел первый релиз qutebrowser - нового браузера на QtWebKit/PyQt5 с vim-like управлением, типа в бозе почивших dwb и luakit, но с тем отличием, что используется не webkit-gtk, а QtWebKit (кто компилировал сам, разницу сразу понимает).
Скриншоты, инструкции, исходный код по ссылке: https://github.com/The-Compiler/qutebrowser
Всем привет, как грамотно реализовать Undo и Redo в программе, где много различных параметров меняется, я думал отслеживать каждый шаг пользователя и записывать в историю, для каждого пункта истории сделать функции Undo и Redo, но тут получается для каждого определенного действия придется наследовать общий класс какой-то, например для удаления объекта, наследуем класс BaseHistoryElement и переписываем функции Undo, Redo в Undo меняем флаг deleted = false; ну и для Redo собственно наоборот. Но с таким подходом очень много кода выйдет для каждого действия, вот и интересно, может есть какой-то более правильный подход?
| ← предыдущие | следующие → |
{kind=link}
{kind=link}